Abstract
Django는 다른 프로그래밍 언어에 비해 쉽게 사용할 수 있는 Python 기반의 Web Framework로, Django를 사용하면 미리 만들어진 강력한 라이브러리들을 그대로 사용할 수 있기 때문에 개발자는 좀 더 쉽고 빠르게 백엔드 서버를 구축할 수 있습니다.
Elasticsearch는 Apache의 Lucene 기반으로 개발된 오픈소스 분산 검색엔진으로 자동완성, 다국어 검색, 철자 수정, 미리 보기 등 Lucene의 강력하고 풍부한 기능을 대부분 지원합니다. 기존의 DBMS에서는 다루기 어려웠던 분야인 전문 검색과 문서의 점수화를 이용한 정렬, 데이터 증가량에 구애받지 않는 실시간 검색 등을 Elasticsearch를 이용해 구현할 수 있습니다. 또한 Elasticsearch는 RESTful API를 지원하므로 URI를 사용한 동작이 가능하고, 필요한 기능에 대한 plug-in을 손쉽게 설치해서 기능을 확장할 수 있는 등 많은 장점들을 가지고 있습니다.
이 글에서는 Python, Django, Elasticsearch를 사용해 Windows 10 환경에서 검색엔진을 구축해보려고 합니다. 그리고 검색 결과에 대한 문제점과 문제를 해결하는 과정까지 다루어보려고 합니다.
목차는 다음과 같습니다.
- 기본 Django서버 구성
- Elasticsearch와 연동하여 백과사전 검색 기능 구현
- 검색 결과의 문제점
- 문제점의 해결 방법
기본 Django서버 구성
먼저, Django를 설치하기 전에 개발 환경을 관리하기 편하도록 가상환경을 생성하려고 합니다. 각각의 가상환경은 독립적으로 관리할 수 있기 때문에 라이브러리 버전 충돌과 같은 문제를 피할 수 있고 가상환경 각각이 변경되어도 서로 영향을 주지 않으며 더 이상 사용하지 않을 경우에는 해당하는 가상환경만 삭제하면 되므로 상당히 편리합니다. 따라서 각 프로젝트마다 별개의 가상환경을 생성한 후 사용하는 것을 추천드립니다.
새 폴더를 만들고 만들어준 폴더 안에서 가상환경을 생성한 후 활성화합니다.
python -m venv myvenv
myvenv\Scripts\activate
pip를 사용해 django와 djangorestframework를 설치합니다.
pip install django
pip install djangorestframework
프로젝트를 만들고 프로젝트 내부에 별도의 애플리케이션을 만들어줍니다.
django-admin.py startproject server_project
cd server_project
python manage.py startapp search_app
INSTALLED_APPS에는 현재 Django 인스턴스에 활성화된 모든 Django 애플리케이션의 이름들이 나열되어 있습니다. 애플리케이션은 다수의 프로젝트에서 사용할 수 있으므로 server_project/settings.py에서 등록을 해야 합니다. Django REST framework를 사용하기 위해 INSTALLED_APPS에 ‘rest_framework’를 추가해줍니다. 위에서 만들었던 ‘search_app’도 추가해줍니다.
# server_project/settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'rest_framework',
'search_app',
]
Elasticsearch와 연동하여 백과사전 검색 기능 구현
‘Elasticsearch와 연동하여 백과사전 검색 기능 구현‘파트는 다음과 같은 순서로 진행됩니다.
- Python ES API, nori 한글 형태소 분석기 설치
- 인덱스 설정 및 생성
- 데이터 삽입
- view 구현
- url 설정
- 검색 결과 확인
Python ES API, nori 한글 형태소 분석기 설치
Python ES API를 이용하면 Elasticsearch를 편하게 사용할 수 있기 때문에 Python ES API를 설치해줍니다. 이 글에서는 elasticsearch 6.3.1버전을 사용합니다.
pip install elasticsearch==6.3.1
Python ES API를 사용하실 때 공식 메뉴얼(https://elasticsearch-py.readthedocs.io/en/master/api.html)을 참고하시면 도움이 많이 됩니다.
Elastic에서 개발한 한국어 형태소 분석기 nori를 이용하기 위해 elasticsearch-plugin 설치를 해줍니다.
C:\Users\user\elasticsearch-6.6.2\bin>elasticsearch-plugin install analysis-nori
인덱스 설정 및 생성
Elasticsearch는 “Hello to the world”라는 문자열을 [“Hello”, “to”, “the”, “world”]로 토크나이징해서 인덱스하기도 하고 중요한 단어인 [“Hello”, “world”]만을 토크나이징해서 인덱스하는 등 유연하게 다양한 방식으로 인덱스를 생성해서 전문 검색에 특히 뛰어납니다.
이를 활용해서 한국어 백과사전 검색에 적합한 인덱스를 생성하기 위해 한글 형태소 분석기 nori를 통해 데이터를 토크나이징할 수 있도록 설정합니다. search_app 디렉터리에 setting_bulk.py 파일을 생성해서 따로 구현해주었습니다.
# search_app/setting_bulk.py
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.indices.create(
index='dictionary',
body={
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer"
}
}
}
}
}
}
)
그다음으로는 mapping 설정을 해주어야 합니다. mapping은 관계형 데이터베이스의 schema와 비슷한 개념으로, Elasticsearch의 인덱스에 들어가는 데이터의 타입을 정의하는 것입니다. mapping 설정을 직접 해주지 않아도 Elastic에서 자동으로 mapping이 만들어지지만 사용자의 의도대로 mapping 해줄 것이라는 보장을 받을 수 없습니다. mapping이 잘못된다면 후에 Kibana와 연동할 때도 비효율적이기 때문에 Elastic에서는 mapping을 직접 하는 것을 권장합니다. 각 필드의 타입을 정의하고 위에서 설정해준 분석기 ‘my_analyzer’로 title과 content를 분석할 수 있도록 설정해줍니다.
# search_app/setting_bulk.py
es.indices.create(
index='dictionary',
body={
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer"
}
}
}
}
},
"mappings": {
"dictionary_datas": {
"properties": {
"id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "my_analyzer"
},
"content": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
}
)
데이터 삽입
백과사전의 일부를 데이터셋으로 활용하였습니다.
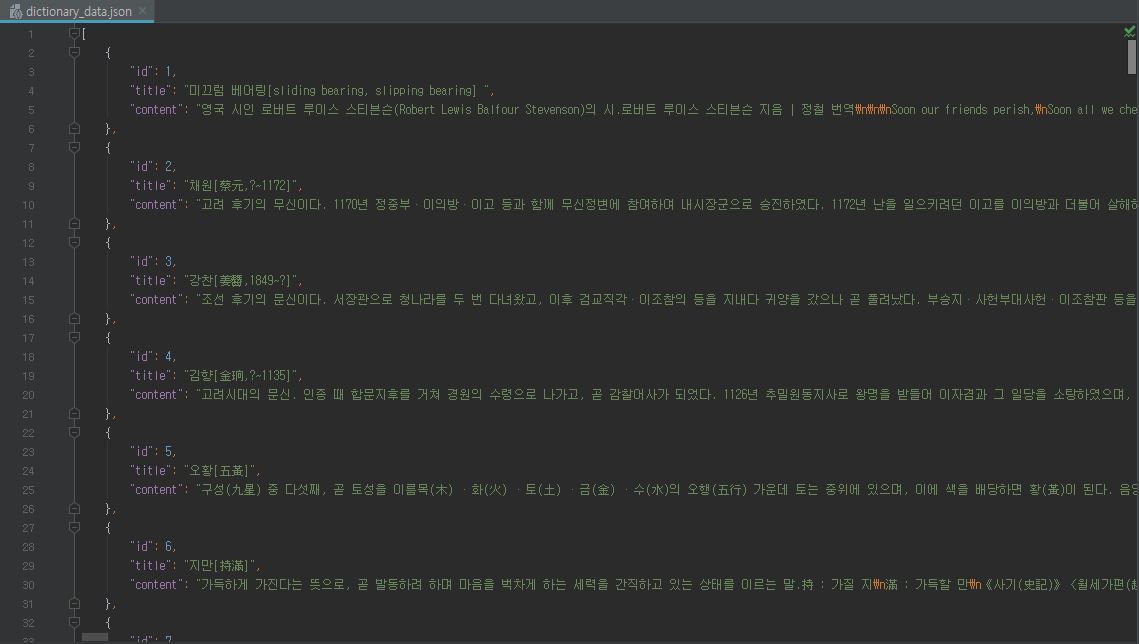 백과사전 데이터셋 JSON파일
백과사전 데이터셋 JSON파일
여러 개의 데이터를 한 번에 Elasticsearch에 삽입하는 방법인 bulk를 사용하여 백과사전 데이터를 Elasticsearch에 삽입합니다.
# search_app/setting_bulk.py
import json
with open("dictionary_data.json", encoding='utf-8') as json_file:
json_data = json.loads(json_file.read())
body = ""
for i in json_data:
body = body + json.dumps({"index": {"_index": "dictionary", "_type": "dictionary_datas"}}) + '\n'
body = body + json.dumps(i, ensure_ascii=False) + '\n'
es.bulk(body)
view 구현
클래스 기반 뷰로 API를 작성할 계획이며 GET Method를 통해 요청을 하면 parameter로 전달된 검색어에 해당하는 검색 결과를 응답하도록 해줍니다.
# search_app/views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import status
from elasticsearch import Elasticsearch
class SearchView(APIView):
def get(self, request):
es = Elasticsearch()
# 검색어
search_word = request.query_params.get('search')
if not search_word:
return Response(status=status.HTTP_400_BAD_REQUEST, data={'message': 'search word param is missing'})
docs = es.search(index='dictionary',
doc_type='dictionary_datas',
body={
"query": {
"multi_match": {
"query": search_word,
"fields": ["title", "content"]
}
}
})
data_list = docs['hits']
return Response(data_list)
url 설정
url의 설정한 부분까지 잘라내고 남은 문자열 부분의 후속 처리를 위해 search_app의 urls.py와 연결해줍니다.
# server_project/urls.py
from django.contrib import admin
from django.urls import path
from django.conf.urls import include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('search_app.urls')),
]
이제 Django는 http://127.0.0.1:8000/로 들어오는 모든 접속 요청을 search_app.urls로 전송해 추가 명령을 찾을 것입니다.
search_app 디렉터리에 urls.py 파일을 생성하고 url 패턴을 추가해줍니다.
# search_app/urls.py
from django.urls import path
from search_app import views
urlpatterns = [
path('', views.SearchView.as_view()),
]
검색 결과 확인
Postman으로 개발한 API를 테스트해봅시다.
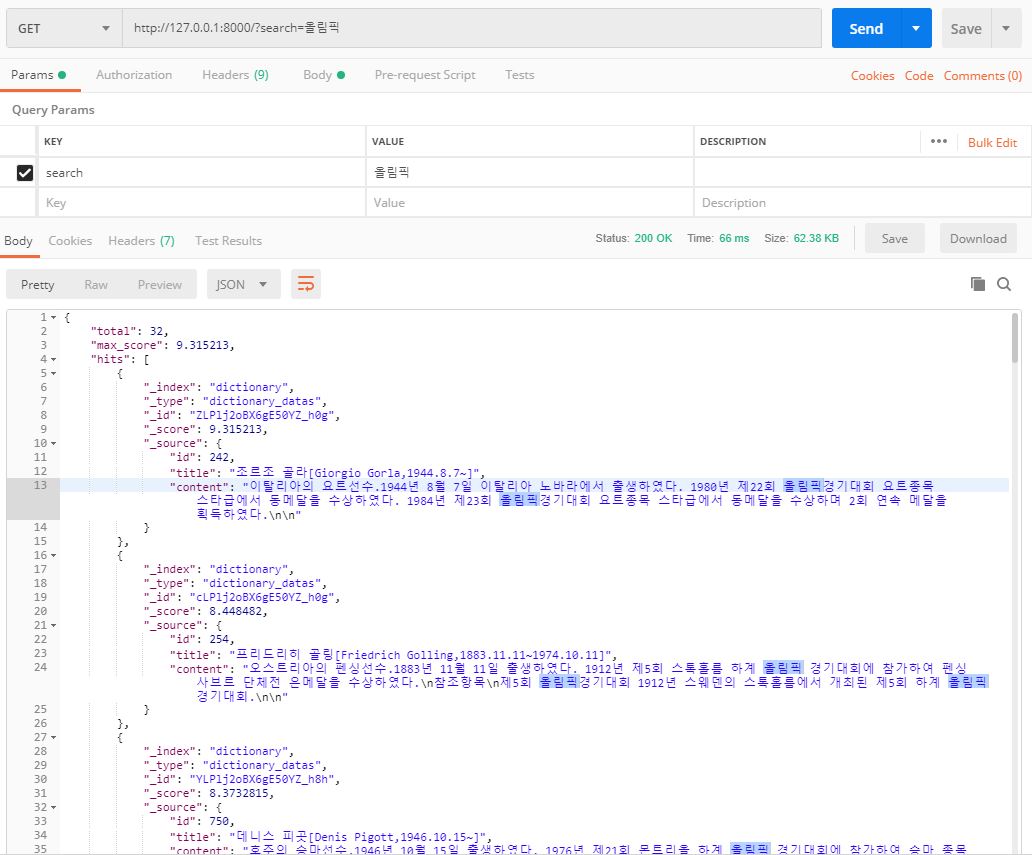 ‘올림픽’으로 검색했을 때 검색 결과
‘올림픽’으로 검색했을 때 검색 결과
다음과 같이 검색어 ‘올림픽’과 관련된 결과가 제대로 출력되는 것을 확인할 수 있습니다.
검색 결과의 문제점
이번엔 한국의 ‘박승희’ 연극인, 극작가님을 검색해봅시다.
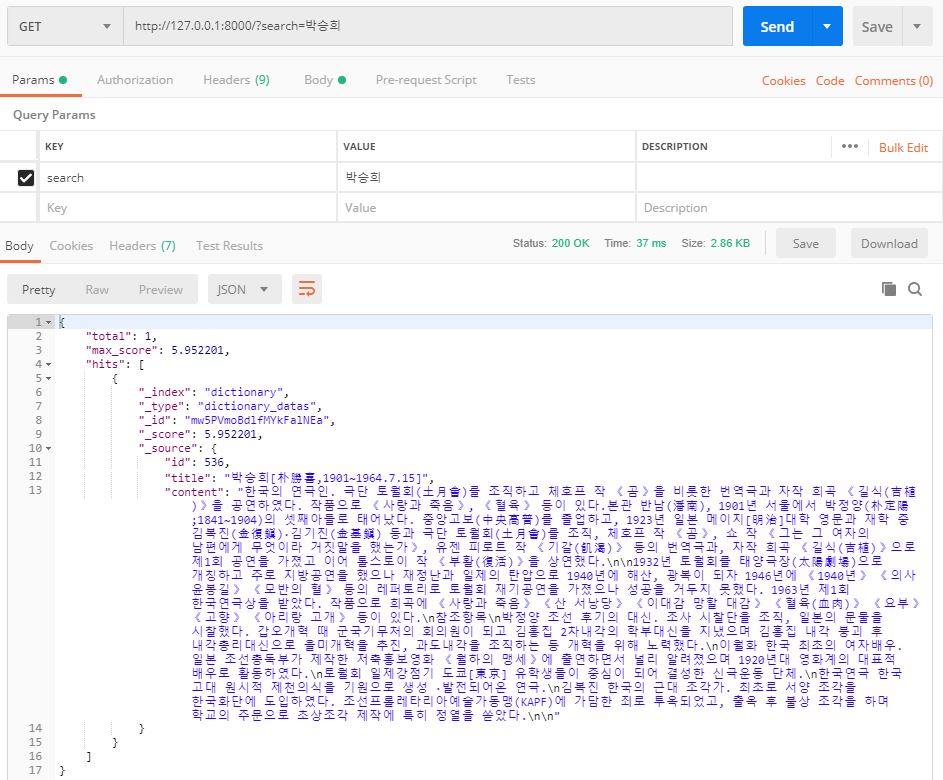 ‘박승희’로 검색했을 때 검색 결과
‘박승희’로 검색했을 때 검색 결과
원하는 결과를 얻을 수 있습니다.
하지만 ‘승희’라고 검색한다면 원하는 결과를 얻을 수 없습니다.
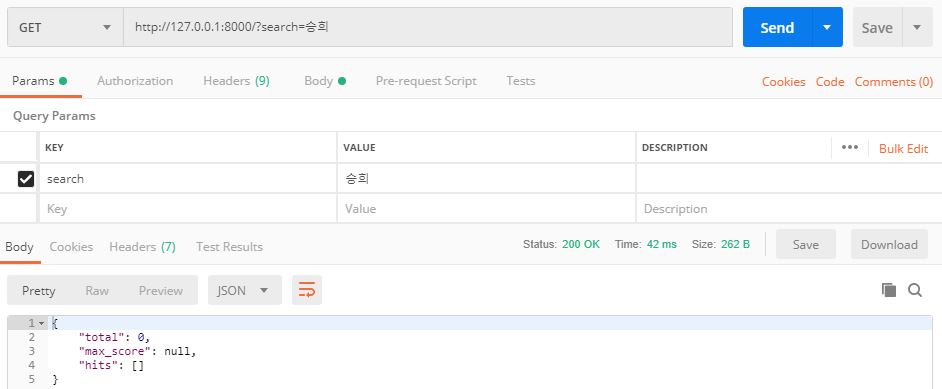 ‘승희’로 검색했을 때 검색 결과
‘승희’로 검색했을 때 검색 결과
이는 nori 형태소 분석기가 한국 이름의 성과 이름을 분리해주지 않기 때문에 발생하는 문제입니다.
 ‘박승희[朴勝喜,1901~1964.7.15]’의 토크나이징 결과
‘박승희[朴勝喜,1901~1964.7.15]’의 토크나이징 결과
이처럼 nori 형태소 분석기가 사용자의 의도와는 다르게 분석을 한다면 고유명사나 신조어와 같은 검색어로 검색을 했을 때 원하는 검색 결과를 얻을 수 없습니다.
문제점의 해결 방법
위와 같은 문제를 해결하기 위해서는 사용자가 고유명사나 신조어를 별도로 정의해두는 사용자 사전을 작성하여 nori 형태소 분석기가 사용자 사전을 참고해서 분석하도록 해야 합니다. 사용자 사전은 아래 그림과 같이 한 줄에 하나의 합성어를 정의하며 한 줄은 합성어 어근 어근 ··· 어근 형태로 whitespace를 구분자로 하여 정의합니다. 어근은 필요에 따라 여러 개를 적으셔도 되고 안 적으셔도 됩니다. txt 파일로 사용자 사전을 작성합니다.
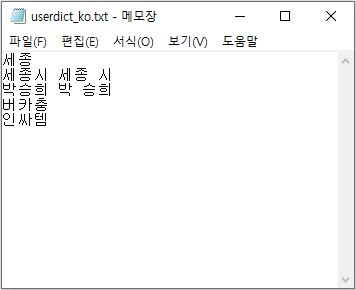 userdict_ko.txt
userdict_ko.txt
Elasticsearch의 config 디렉터리에 저장합니다.
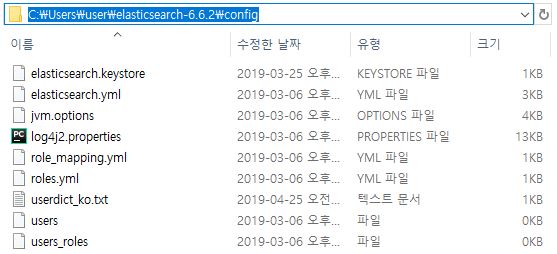 “C:/Users/user/elasticsearch-6.6.2/config”에 저장된 모습
“C:/Users/user/elasticsearch-6.6.2/config”에 저장된 모습
이제 작성한 사용자 사전을 nori 형태소 분석기에 적용시킵니다. setting_bulk.py의 분석기 설정 부분을 다음과 같이 수정합니다.
# search_app/setting_bulk.py
"settings": {
"index": {
"analysis": {
"tokenizer": {
"nori_user_dict": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"user_dictionary": "userdict_ko.txt"
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "nori_user_dict"
}
}
}
}
}
이제 ‘dictionary’ 인덱스를 삭제하고 setting_bulk.py를 실행시켜 다시 백과사전 데이터를 삽입합니다. 그리고 Postman에서 ‘승희’라는 검색어로 검색을 해보면 원하는 검색 결과가 제대로 출력되는 것을 확인할 수 있습니다.
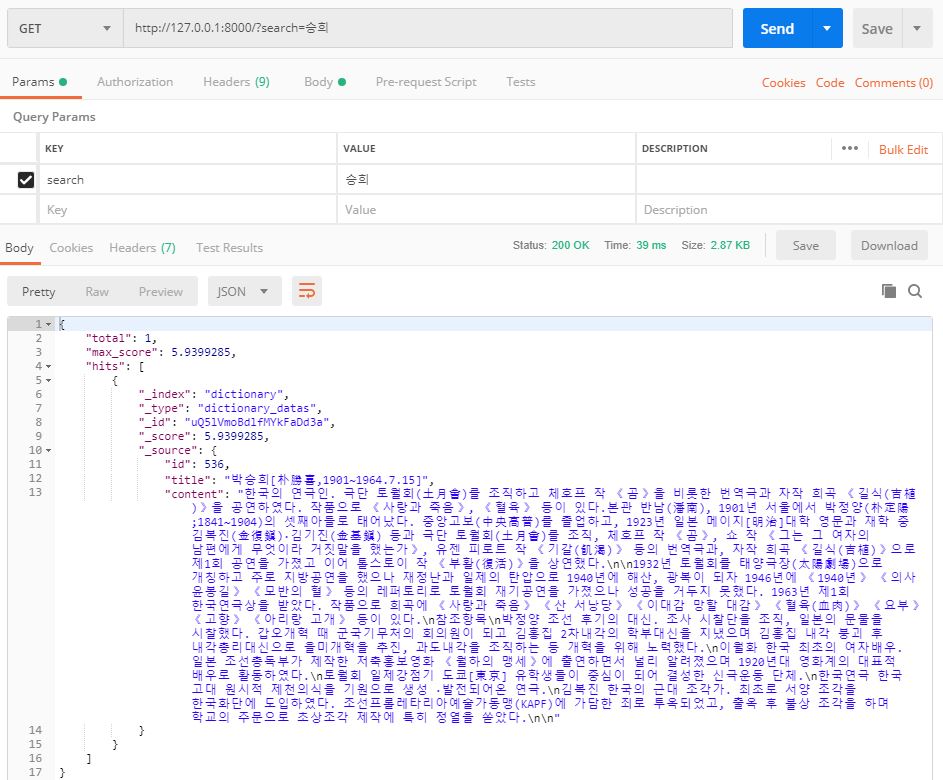 ‘승희’로 검색했을 때 검색 결과
‘승희’로 검색했을 때 검색 결과
 ‘박승희[朴勝喜,1901~1964.7.15]’의 토크나이징 결과
‘박승희[朴勝喜,1901~1964.7.15]’의 토크나이징 결과
Result
파라미터로 검색어를 전달해서 백과사전을 검색하는 간단한 검색엔진을 구축해보았습니다. 그리고 사용자 사전을 적용하여 기본 nori 형태소 분석기가 토크나이징하지 못하는 고유명사나 신조어를 사용자의 의도대로 토크나이징하여 원하는 검색 결과를 얻을 수 있도록 하는 방법에 대해서도 알아보았습니다. 언어는 고정불변의 것이 아니라, 시대에 따라 생성, 변화, 사멸합니다. 빠르게 변화하는 시대 속에서 이와 같은 사용자 사전기능은 더욱 중요해질 것입니다.
References
[1] https://tutorial.djangogirls.org/ko/
[2] https://www.django-rest-framework.org/
[3] https://www.elastic.co/guide/index.html
[4] https://elasticsearch-py.readthedocs.io/en/master/api.html