Abstract
검색도구를 이용하는 고객들의 단순한 키워드만으로 검색 의도를 완벽하게 파악하기 어려운 경우가 많습니다. 하지만 유사 이미지 분류기술을 활용한 이미지 검색 기술은 고객이 직접 대상의 특징을 서술하지 않아도 특정 이미지를 입력하여 이와 유사한 이미지를 분류하고 검색도구에 힘을 실어 줄 수 있는 기술입니다.
이번 글에서는 이러한 검색 자료에 활용될 수 있고 사용자의 이미지 객체를 인식하여 기존에 데이터베이스에 저장된 객체와 얼마나 유사한지 분류하기 위한 방법인 유사이미지 분류 기술을 학습하고 구현한 방법을 소개하려고 합니다.
앞서 큰 틀이 되는 인공지능 기술인 전이학습(Transfer Learning)과 전이학습에 사용될 모델의 이해, 학습용 데이터셋에 대해 어떻게 이해하고 활용 했는지에 대한 내용을 기술합니다.
1. 전이학습 기술이해 & 학습을 위한 모델 선정
1-1. 전이학습 이해
⇒ ‘유사 이미지 분류’ 기술을 구현하는데 앞서 큰 틀은 전이학습(Transfer Learning)기반이 되며 이 기술은 특정 Task 또는 도메인에서 얻은 모델을 다른 Task에 적용하는 기술로, 이미 학습된 모델의 가중치를 가져와서 분류하고 싶은 다른 데이터셋에 적용하는 것으로 이해할 수 있습니다.
전이학습을 사용하는 세가지 특징
- 적은 데이터셋을 사용하여 모델 학습
- 대부분의 경우 전이학습한 모델이 처음부터 쌓은 모델보다 성능이 뛰어나다.
- 시간이 절약이 된다.
처음에 위의 특징 중 2번이 이해가 되지 않았습니다. ‘왜 내가 다루고자하는 데이터셋을 기존에 다른 데이터셋에 맞추어 학습된 모델에 학습을 시키는데 처음부터 쌓은 모델보다 성능이 좋을까?’ 라는 의문이 들었습니다.

질문에 대한 해답은 딥러닝은 “계층적인 특징”을 “스스로” 학습한다. 라는 점이 었습니다. 모델의 low level layer는 general feature를 추출하고 모델이 쌓여갈 수록 high level layer에서는 specific한 feature을 추출해내는 고도화된 학습이 이루어집니다. 따라서 초기 layer의 general feature들은 학습할 때 재사용해도 되지만 후반부에 위치한 layer의 specific feature들은 재학습이 필요합니다.
예를 들어 쉽게 설명하자면 MNIST와 같은 데이터셋에 따라 학습을 시킨 모델의 경우, 초기 layer는 직선이나 곡선 같은 general한 feature를 추출할 것이고 이렇게 추출된 feature map은 한글이나 영어문자에 대한 데이터셋에도 효과적으로 재사용할 수 있다고 추측하는 것입니다.
전이학습의 주요 키워드 세가지
전이학습을 이해하는데 있어서 주요한 세가지의 키워드가 있습니다.
-
ConvNet as fixed feature extractor(=고정 기능 추출기)
⇒ 처음에는고정기능추출기라는 용어를 이해하는데 힘들었던 것 같습니다. 하지만 이해를 한다면 왜 고정기능추출기이라고 불리는지 금방 이해할 수 있습니다. 예를 들어 어느 특정 데이터셋에 대해 이미 학습된 ConvNet 모델을 가져온 후 위에 특징 2번에서 말했듯 초기 layer는 고정합니다. 후에 마지막 Classifier부분을 제거하고 새로 분류하고 자하는 데이터셋의 카테고리 수에 맞게 초기화 해주는 것입니다.
-
Fine-tuning the convNet(=미세조정)
⇒ 두 번째 키워드인 Fine-tuning은 고정된 부분도 학습을 재진행할 수 있지만 교체한 마지막 fc(fully-connected)부분만 다시 재학습을 시켜주는 것 뿐만 아니라 역전파를 계속하는 것을 뜻하기에 ‘미세조정’이라는 말을 쓴 것 같습니다. 참고로 ConvNet의 모든 계층을 fine tuning하거나 초기 layer 중 일부를 고정상태로 유지할 수 있습니다. 초기 layer 중 일부를 고정하는 것은 overfitting문제를 방지하기도 합니다.
-
Pretrained models
⇒ model의 weight를 공유해서 fine-tuning하는 것은 시간이 절약된다는 장점이 있습니다.
fine-tuning을 어떤 상황에서 해야하는지에 대한 4가지 시나리오
신경써야할 두가지 중요한 요소는 아래와 같습니다.
- 데이터셋의 크기
- pretrained된 모델에 사용한 데이터셋과의 유사도
데이터셋에 따른 4가지 시나리오
| New Dataset |
크기 |
유사도 |
fine-tuning 적용여부 |
| A Dataset |
small |
high |
데이터셋이 너무 작아 ConvNet의 overfitting문제를 해결하려고 fine-tuning을 하는 것은 좋지 않은 생각이입니다. 원본 데이터셋과 유사도가 높기때문에 higher-level의 feature가 새 데이터셋과 관련이 있을 것으로 예상되며 linear classifier만 train시키는 쪽으로 생각하면 됩니다. |
| B Dataset |
small |
low |
linear classifier만 학습하는 것이 좋은 방법입니다. 또한 데이터셋이 매우 다르기에 후반부의 layer만 fine-tuning하는 것은 좋은 방법이 아니며 초기 layer에서 재학습하는 것이 효과적일 수 있습니다. |
| C Dataset |
big |
high |
이 경우는 문제가 되는 부분이 없습니다. 다만 fine-tuning만 해주면 overfit하지 않을 것이라는 확신만 있을 뿐입니다. |
| D Dataset |
big |
low |
fine-tuning 수행의미가 없다고 생각합니다. 처음 부터 모델링을 만드는 것이나 마찬가지 이기 때문입니다. |
실습은 PyTorch.org 사이트에서 전이 학습에 대한 코드를 Colab, Jupyter notebook, GitHub으로 공유하고 있고 이 공유된 코드를 통해 전이학습에 대한 이해를 깊게 할 수 있습니다. → 실습링크
1-2. DenseNet 모델 선정
ResNet과 DenseNet
ResNet은 2015년에 열린 ILSVRC에서 등장해 우승을 차지한 이미지 분류 모델로 깊은 네트워크 층으로 부터 생기는 학습 에러와 복잡도 문제를 해결하기 위해 고안되었습니다.
입력에서 바로 출력으로 연결되어 기존의 출력값(H(x))에서 입력값(x)을 뺀 차이를 얻기 위해 학습하는 (출력 : H(x) = F(x) + x) Skip Connection이라는 개념을 도입해서 높은 수준의 정확도를 보여주게 되었습니다.
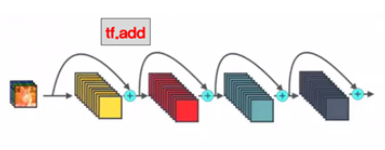
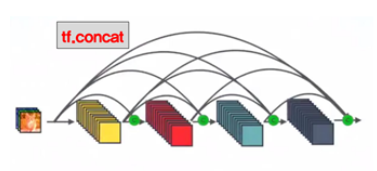
- (좌) Resnet의 설계 구조, (우) Densenet의 설계구조
그러던 중 레이어 간 정보 흐름을 좀 더 자연스럽게 한 DenseNet의 등장은 이러한 Skip Connection을 빽빽하게(Dense) 늘려서 핵심 특징을 잘 추출하는 동시에 그레디언트 소멸 문제에도 대응하도록 보완하며 발전하게 되었습니다.
이러한 바탕 속 ResNet을 비롯한 이전 전통적인 CNN모델과 차별되는 특징 추출 능력은 DenseNet이 저희의 트레이너 모델로 선정하는 계기가 되기도 하였습니다.
모델을 탐구하는 이유
: 보통 Pytorch나 Keras 같은 라이브러리에서 제공하는 모델을 호출할때는 기본적으로 필요한 parameter값만 확인해 적절히 넣어주면 문제 없이 동작하는 모습을 보여줍니다.
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
squeezenet = models.squeezenet1_0(pretrained=True)
vgg16 = models.vgg16(pretrained=True)
densenet = models.densenet161(pretrained=True)
inception = models.inception_v3(pretrained=True)
googlenet = models.googlenet(pretrained=True)
hufflenet = models.shufflenet_v2_x1_0(pretrained=True)
mobilenet = models.mobilenet_v2(pretrained=True)
resnext50_32x4d = models.resnext50_32x4d(pretrained=True) wide_resnet50_2 = models.wide_resnet50_2(pretrained=True)
sresnext50_32x4d = models.resnext50_32x4d(pretrained=True) wide_resnet50_2 = models.wide_resnet50_2(pretrained=True)
mnasnet = models.mnasnet1_0(pretrained=True)
torchvision에 models 하위 카테고리에만 해도 이렇게 다양한 모델을 버전별로 호출해서 사용할수 있기에 일반적으로 학습을 위한 데이터만 구축되있다면 이미지 분류, 처리 분야에 있어서 검증된 모델을 통해 원하는 카테고리에 대한 학습을 진행할수 있습니다. 하지만 직접적으로 기존 모델을 커스터마이징 할필요가 생긴다면 라이브러리로 불러오는 모델의 내부 구조와 코드를 어느정도 이해하는 편이 도움이 될 수 있을 것입니다.
예를들어 다양한 모델을 적용한 것같은 효과를 볼수 있는 DropOut을 적용하거나 학습 속도를 빠르게 하기 위해 일부분을 변경한다던가 하는 상황이 충분히 있을 수 있기 때문입니다.
목표로 설정된 트레이너 제작에서도 사용자 혹은 협업자의 편의성 및 성능 향상 등을 목적으로 한 커스터마이징 작업을 위해선 구조를 제대로 파악해 엉뚱한 코드를 건드리지 않도록 혹은 모델의 구조와 구조에 대응하는 코드에 대해 전반적인 이해가 필요할 것입니다.
사용할 torchvision의 DenseNet모델에 대한 코드 분석을 진행해보도록 하겠습니다.
Densenet 의 아키텍처
github.com/pytorch/vision/blob/master/torchvision/models/densenet.py
→ 트레이너애 사용된 modeling_densenet.py 코드의 전신인 torchvision densenet의 원본 코드
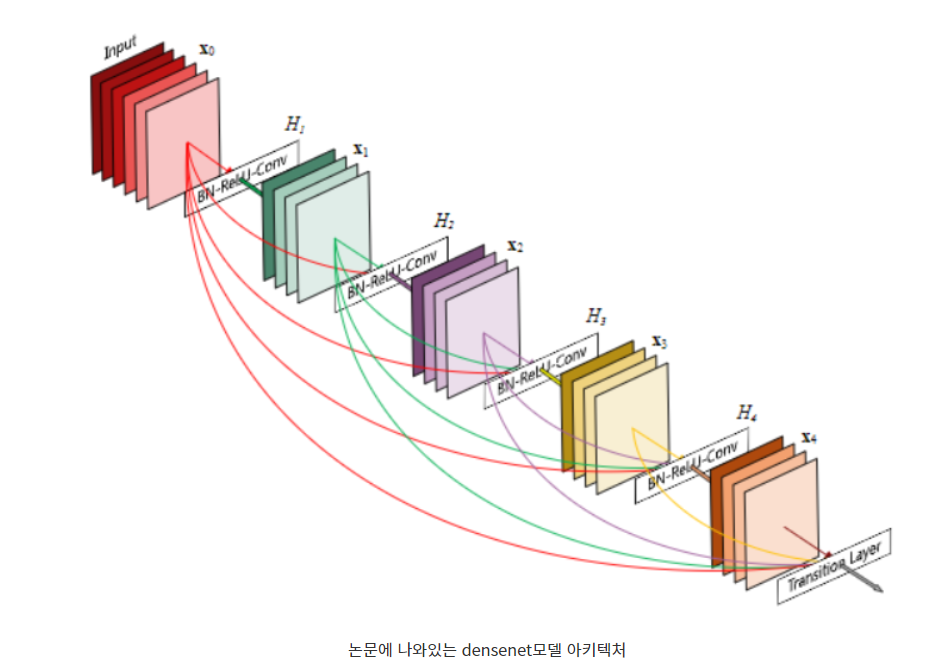
코드를 살펴보기 전에 먼저 Densenet의 구조와 특징에 대해서 알아보도록 하겠습니다.
사진에서 나와있는 것처럼 Resnet을 이미 접해본 분들에게는 살짝 익숙한 느낌이 들수 있는 설계 구조가 나타납니다. 차이점이라면 Resnet은 직전 레이어의 입력 값만 출력에 반영되어 다음 레이어로 가는 입력에 반영되는 반면 Densenet은 직전 레이어 입력 뿐 아니라 블록 내에서 거처간 레이어들이 모두 다음 레이어 입력에 반영된다는 특징을 가지고있습니다. 텐서의 차원같은 느낌인 채널이 블록이 끝날 때까지 지속적으로 쌓이는 구조라 생각하시면 될 것 같습니다.
arxiv.org/pdf/1608.06993.pdf → 포스팅에 바탕이 된 원본 논문
만약 Block내에 x개의 레이어가 존재한다면 Resnet에서는 각 레이어 당 1개 총 x개의 지름길이 형성되지만 densenet은 각 레이어 당 1, 2, 3 … 참조하는 이전 레이어 입력(초기 입력되는 채널 포함 )이 1씩 증가하는 등차수열로 형성되어서 등차수열의 합 공식을 적용하면 총 x(x+1)/2 개의 지름길이 형성됩니다.
논문에서는 이러한 Densenet의 강점으로 이러한 부분을 소개하고 있습니다.
- alleviate the vanishing gradient (-> 그레디언트 소멸 문제 완화)
- strengthen feature propagation (-> 강력한 특징 전파력)
- encourage feature reuse (-> 특징 값 재사용 활성화)
- substantially reduce the number of parameters (-> 계산량을 줄이기 위해 필요한 파라미터 갯수 감소)
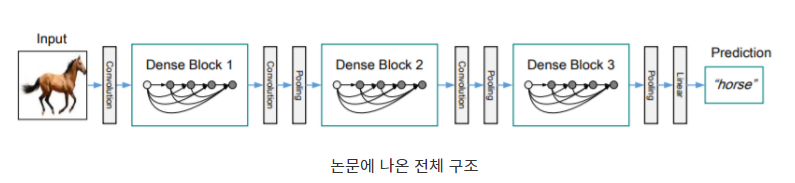
위에 사진은 Densenet전체의 한 블록 내의 구조를 표현한 것이며 3개의 Block이 합쳐진 전체 구조를 표현한 논문 내의 그림입니다. 비록, 그림에는 3개의 블록이 표시되었지만 이번에 사용할 torchvision의 기본적으로 block의 갯수는 4개의 형태를 보여줍니다.
마지막 블록을 제외하면 Transition Layer라고 불리는 배치 정규화 + Relu 활성함수+ 1x1 컨볼루션을 거치는 구조로 이루어진 합성합수와 평균 풀링으로 이루어진 레이어가 등장하는데, 위에서 계속 지나간 이전 레이어들의 입력 값을 반영하다 보면 다음 레이어가 들어갈 입력값의 채널이 지나치게 비대해 질수 있습니다.
각 레이어의 입력에는 파이토치의 텐서가 들어가는데 Transition Layer는 이 텐서의 채널을 반토막으로 줄여주고 이미지 사이즈에 해당하는 크기를 1/4로 줄여줍니다. 안에 있는 평균 풀링의 보폭이 기본적으로 2 이므로 1/4사이즈로 줄어드는 것이고 보폭을 늘리면 1/보폭의 제곱 만큼 사이즈가 줄어들 것입니다.
채널 수의 증가는 파라미터의 증가로 이어져 계산량이 폭발적으로 늘어나게 되는데 1x1컨볼루션은 채널을 줄여줘 우리들의 GPU(혹은 CPU)와 RAM 연산 부담을 줄여주는 담당해주며 이렇게 채널을 줄였다 늘렸다 조절하는 구조를 bottleneck구조라고 합니다.
마지막에 Linear라고 표시된 부분은 마지막 block을 지나고 출력된 채널 수 만큼의 1차원 텐서가 분류하고 싶은 속성 값에 해당되는 Tensor 배열(torchvision에서의 default값은 1000)에 각각 Fully Connect를 해주는 부분으로 이번에 전이학습을 통해 트레이너를 제작할시 바꿔줄 부분입니다.
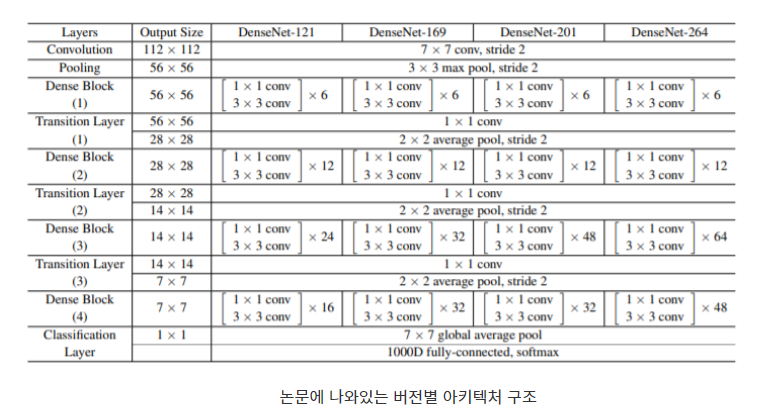
마지막으로 알아둬야 할 부분은 Densenet버전에 따라서 모델 내의 레이어 수가 달라진다는 점 입니다. 트레이너에 사용할 121모델 같은 경우는 각 블록 마다 6(첫번째), 12(두번째), 24 ,16의 레이어로 구성되어있으며 169 모델은 6, 12, 32, 32의 레이어 숫자를 가진 블록으로 구성되어 있는 등 버전 마다 레이어 수가 조금씩 다르고 경우에 따라선 모델 내 입출력 텐서도 다를수 있습니다.
객체 지향적 모델 코드
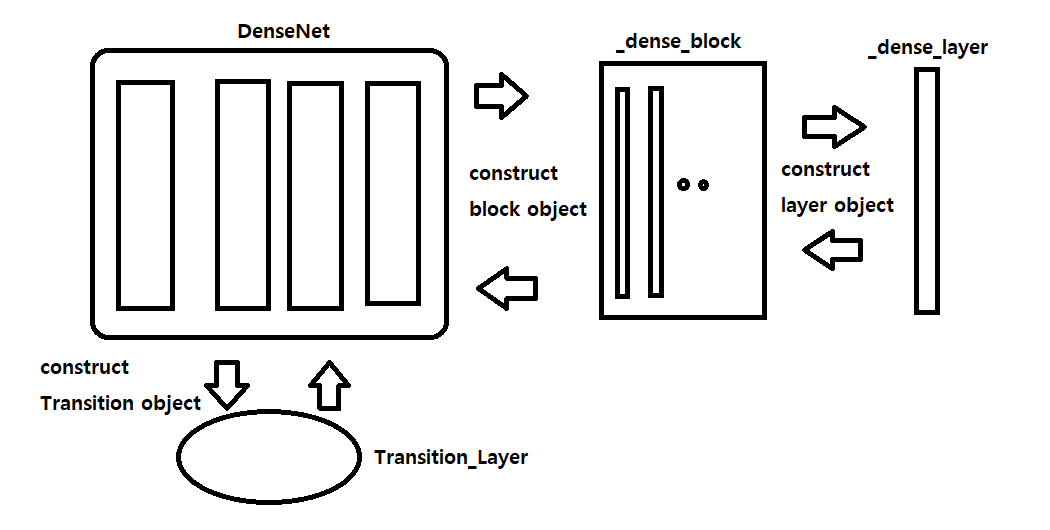
torchvision 내의 densenet.py코드는 이러한 레이어 , 블록, 그리고 본체의 모델은 각각 class로 선언되어 상위 객체가 하위객체를 호출하는 객체지향적 방식으로 구성되어 있습니다.
전반적인 Densenet의 구조와 특징을 알아보았다면 코드를 살펴보도록 하겠습니다.
class DenseNet(nn.Module):
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16),
num_init_features=64, bn_size=4, drop_rate=0, num_classes=1000, memory_efficient=False):
super(DenseNet, self).__init__()
# First convolution
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2,
padding=3, bias=False)),
('norm0', nn.BatchNorm2d(num_init_features)),
('relu0', nn.ReLU(inplace=True)),
('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]))
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock( # block객체 생성
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
memory_efficient=memory_efficient
)
self.features.add_module('denseblock%d' % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1: # transition layer객체 생성
trans = _Transition(num_input_features=num_features,
num_output_features=num_features // 2)
self.features.add_module('transition%d' % (i + 1), trans)
num_features = num_features // 2
# Final batch norm
self.features.add_module('norm5', nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
인자로 들어가는 파라미터 중 핵심 요소에 대한 짧은 설명을 하자면
- growth_rate : 각 레이어에서는 growth_rate크기 만큼의 고정된 크기의 채널을 가진 텐서를 output으로 출력합니다. 아까 위에서 이전 레이어들의 입력 값들이 반영되 채널이 쌓이게 되는 것이 Densenet의 핵심인데 growth rate를 직역하면 성장률이 되기때문에 채널의 성장을 표현한 네이밍이 될 것 같습니다.
- block_config : Densenet에 들어갈 block들의 레이어 수를 튜플로써 표현한 것으로 기본 default값은 6, 12, 24, 16으로 121버전이 설정되어있음을 알수 있습니다. (첫 블록은 6개 두번째는 12개 세번째는 24개 네번째는 16개의 레이어로 이루어짐)
- num_init_features : 처음으로 입력 값이 들어가는 Convolution층에는 3개의 채널로 이루어진 이미지 텐서가 들어가게 됩니다. 3가지 채널은 빛의 3원색인 RGB를 뜻해서 3개의 채널인데 이 입력 텐서를 처음에 몇 채널로 바꿔줄지 결정하는 역할을 수행합니다.
- num_classes : 분류하려는 클래스의 갯수를 의미합니다. 여기서는 default값이
ImageNet이 생각나는 1000이라 그냥 모델을 인자를 수정해주며 활용만 하는게 목적이라고 해도 이 부분은 직접 설정을 해주어야합니다.
class _DenseBlock(nn.Module):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate, memory_efficient=False):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer( # layer객체 생성
num_input_features + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.add_module('denselayer%d' % (i + 1), layer)
모든 블록, 레이어를 포함하는 상위 객체인 DenseNet클래스가 하위 객체인 dense_block과 trainsition_layer를 호출하고 dense_block이 자기 보다 하위 객체인 dense_layer를 호출하는 자료구조의 Tree 프론트엔드의 DOM같은 구조를 띄고 있습니다.
2. 구현한 내용 및 결과
2-1. 모델 세팅
모델 초기화
def __init__(self, property, hyper_parameter, class_length):
self.class_length = class_length
self.property = property
self.hyper_parameter = hyper_parameter
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
with open(self.property['config_file'], "r", encoding='UTF-8') as i:
densenet_cfg = json.load(i) # config_file : model의 hyper parameter
# Prepare Model
print("Loading DenseNet121 network.....")
self.model = DenseNet(
growth_rate=densenet_cfg["growth_rate"],
block_config=tuple(densenet_cfg["block_config"]),
num_init_features=densenet_cfg["num_init_features"]
)
self.model.load_state_dict(torch.load(property['weight_file'], map_location=self.device)) # 모델에게 가중치 부여
: 위에 설명한 yaml파일에서 미리 설정해둔 값을 property 변수에 담아서 필요한 파일에 대한 참조를 진행합니다. 그 중 모델에 대한 초기 설정을 가지고 있는 config파일을 가져와 원하는 값으로 설정 및 초기화를 진행해줍니다.
- 마지막 classifier 분리 후 데이터셋의 카테고리 수에 맞도록 초기화 해주는 부분
'''
여기서 각 출력의 크기는 데이터셋의 카테고리 수로 설정합니다.
nn.Linear(num_ftrs, len (class_names))로 일반화할 수 있습니다.
output을 parameter로 받아주도록 해야한다!!
'''
num_ftr = model_conv.classifier.in_feature
model_conv.classifier = nn.Linear(num_ftr, self.class_length)
: 분류기에 대한 전이 학습에 알맞게 기존 densenet 가중치 파일이 적용된 classifier 부분을 랜덤한 가중치를 가진 Fully Connected부분으로 초기화 시켜주는 것이 핵심입니다.
해당 부분을 통해 분류를 원하는 카테고리에 따라서 다르게 Classifier를 학습 후 적용하는 것이 가능해집니다.
2-2. 트레이너 설정, 학습 및 평가
Buster’s trainer
def train_classifier(self, learning_rate=0.00005, epoch=10, batchs=8):
'''해당 파일의 알파이자 오메가. 이미 학습되있는 모델 본체의 pth파일과 학습이 필요한 classifier를
불러와 머신러닝을 진행한다. 중간중간 validate_and_save함수를 호출해 평가를 진행하고 필요시 저장한다'''
train_data = torchvision.datasets.ImageFolder(root=address_book['train_address'],
transform=self.preprocess)
data_loader = DataLoader(train_data, batch_size=batchs, shuffle=True, drop_last=False)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(self.model.classifier.parameters(), lr=learning_rate)
...
⇒ 먼저 여타 다른 모델 훈련처럼 위에 설명한 yaml파일에 설정한 학습 데이터의 경로에서 ImageFolder 함수를 이용하여 카테고리 이름으로 명명된 디렉토리로 구분된 이미지 데이터들을 가져옵니다. 만약 이미지 데이터 이외에 데이터의 경우 해당 파일은 ImageFolder함수에서 자동으로 필터링됩니다. 데이터를 카테고리 분류별로 불러오고 학습을 위해 다음 두 가지를 추가로 수행해야 합니다.
-
dataloader에서 마찬가지로 사전에 설정한 batch_size를 가져와서 해당 batch_size만큼 ImageFolder로 가져온 데이터들을 나눈 후 나머지 부분을 drop하는 경우 없이 섞어줍니다.
-
criterion(목적함수 혹은 손실함수)과 optimizer로는 각각 교차 엔트로피와 dagrad와 RMSProp의 장점을 합친 Adam을 설정해줍니다. Adam에 경우 step의 크기나 그레디언트의 크기에 영향을 받지 않으며 어떤 목적 함수에도 호환되고 안정적인 최적화를 위한 하강이 가능하다는 장점을 가지고 있는게 눈에 띄어서 선택하게 되었습니다.
-
추가로 현재 트레이너에서는 오직 분류기 부분만 학습을 진행할 것이기 때문에 생성자 부분에서 따로 분리한 객체 내 classifier의 가중치만 optimizer에 넣어주도록 해야합니다.
추가적으로,학습률(learning_rate) 또한 yaml에서 설정 가능합니다.
def train_classifier(self, learning_rate=0.00005, epoch=10, batchs=8):
...
for i in range(epoch):
for batch_idx, samples in enumerate(data_loader):
x, y = samples
x = x.to(self.device)
y = y.to(self.device)
prediction = self.model(xx)
cost = criterion(prediction, y)
optimizer.zero_grad()
cost.backward()
optimizer.step()
...
⇒ dataloader에 저장된 이미지 tensor 값과 카테고리 번호에 해당하는 값을 x와 y에 저장하고
→ device등록
→ 생성자의 model에 넣고 block과 각종 레이어를 거쳐 순전파된 결과를 원래 카테고리 번호와 비교
→ 교차 엔트로피를 통해 오차를 계산하고 해당 오차(손실)값을 이전 레이어에 역전파
등의 과정을 반복하며 트레이너의 학습이 진행됩니다.
def train_classifier(self, learning_rate=0.00005, epoch=10, batchs=8):
...
if (count % (batchs * save_step)) == 0 and i >= minEpoch_toSave:
print("You just activate my val Card")
models_score = self.validate_and_save(models_score, i + 1, int(count / batchs))
# in more than three epoch statem every 100 step, save weight file temporary
...
self.validate_and_save(models_score, epoch, 0)
( ※ minEpoch_toSave는 yaml파일에서 설정하는 속성으로 평가를 진행하기 위해 순회해야할 최소 epoch수를 의미합니다. 즉, 아직 데이터를 전체적으로 보지 못해 학습이 안된 초기부터 평가를 진행하면 무의미한 결과가 나올 가능성이 높아서 일정량의 학습이 이루어진 후 평가가 진행되기 위해 설정한 속성 )
⇒ 설정된 batch_size를 1step으로 해서, epoch마다 평가를 원하는 일정 step수가 지나면 따로 저장된 검증 데이터를 통해 정확도 평가를 진행하고 이전보다 개선된 결과가 나오면 현재 가중치 상태를 저장합니다.
마지막 코드 라인에서 사용자가 설정한 step주기 뿐 아니라 학습 종료 시에도 평가를 진행하며 정확도에 개선되었을 경우 모델 가중치의 최종본을 따로 저장해둡니다.
def train_classifier(self, learning_rate=0.00005, epoch=10, batchs=8):
...
if (i + 1) % reduceLR_term == 0 and i != 0:
learning_rate = self.reduce_LR(learning_rate)
optimizer = torch.optim.Adam(self.model.classifier.parameters(), lr=learning_rate)
# for prevent overfitting, adaptive learning rate used
...
def reduce_LR(self, learning_rate):
'''적응적 학습률을 구현. train함수에게 호출되며 사용자가 임의로 조절 가능하다.'''
lr = learning_rate * (85 / 100)
print('reduce learning rate to', lr)
return lr
( ※ reduceLR_term은 yaml파일에서 학습률을 조정할 epoch 주기를 설정하는 속성입니다. )
⇒ 추가적으로 적응적 학습률을 도입하여 사용자가 설정한 일정 epoch주기마다 현재 학습률을 15% 감소시키는 기능을 추가하였습니다. 해당 기능을 통해 경사하강법(Gradient Descent With Momentum)에서 진동을 줄이는 것처럼 모델 내에서 미세한 조정을 가능하게 해서 더 정확한 결과를 유도하게 됩니다.
Jo’s trainer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), hyper_parameter["learning_rate"], hyper_parameter["momentum"])
scheduler = lr_scheduler.StepLR(optimizer, hyper_parameter["step_size"], hyper_parameter["gamma"])
⇒ 손실함수와 optimizer를 학습을 진행하기전에 설정하며 optimizer와 scheduler에 사용되는 parameter 값은 위의 yaml파일에서 설정한 값입니다.
-
- criterion
- 손실함수는 CrossEntropyLoss를 사용합니다.
-
- optimizer
- SGD(Stochastic Gradiant Descent)를 사용하여 mini batch에 대해서 손실함수를 계산하고 최적점으로 이동하는 과정에서 Momentum이라는 성질을 이용한다는 특징이 있습니다.
이 특징은 mini batch에 대해 손실함수를 계산하고 weight 업데이트를 하기에 learning rate가 작아도 업데이트되는 weight가 noisy합니다. Momentum알고리즘을 추가하여 업데이트되는 weight의 비율을 줄여 일부 데이터의 모음만 가지고 효과적으로 weight를 갱신합니다.
-
- sheduler
- Learning Rate Scheduler를 사용하면 좀 더 효율적으로 Global Minimam에 수렴할 수 있도록 도와줍니다.
best_model_wts = deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
for phase in ['train', 'val']: # train mode와 validation mode순으로 진행
if phase == 'train':
model.train() # 모델을 train 모드로 설정
else:
model.eval() # 모델을 eval(=val) 모드로 설정
running_loss = 0.0
running_corrects = 0
# 데이터를 반복
step = hyper_parameter["user_step"] # yaml파일에서 정한 step을 기준으로 평가 및 기록
total_step = hyper_parameter["user_step"]
best_step_acc = 0.7 # step마다 정확도를 최초에 평가할때 최소 0.7을 넘겨야 함
for index, data in (enumerate(tqdm(dataloaders[phase]))):
inputs = data[0].to(device)
labels = data[1].to(device)
# 매개변수 Gradiant를 0으로 초기화
optimizer.zero_grad()
# 순전파(foward)
# 학습 시(train)에만 연산 기록을 추적
# CustomModel클래스에서 모델생성시 결정됨
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 학습 단계인 경우 역전파 + 최적화
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if index > 0 and index % step == 0 and phase == 'val':
step_acc = running_corrects.double() / (hyper_parameter['batch_size'] * total_step)
total_step = total_step + step # step을 일단 10으로 지정 --> 나중에 step이라는 hyper parameter표시
if step_acc > best_step_acc:
best_step_acc = step_acc
best_step_wts = deepcopy(model.state_dict())
if phase == 'train':
scheduler.step()
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = deepcopy(model.state_dict()) # 높은 정확도일때 weight를 저장
# 가장 나은 모델 가중치를 불러옴
model.load_state_dict(best_model_wts)
# 가장 나은 모델 가중치를 저장
weight_save_path = property["model_weight_file"]
torch.save(best_model_wts, weight_save_path)
⇒ 학습(Training)과 검사(Test or Val)을 나누지 않고 한 테스크로 이루어지도록 구성하였습니다. 이런 구성은 매epoch마다 train, test 정확도를 확인을 하며 최적의 epoch값을 구할 수 있습니다.
→ 먼저, 한 에폭을 돌때 train인지 val인지 따라 모드가 설정되며 train일 경우에만 역전파와 최적화를 해주도록 되어있습니다.
→ 중간에 step변수를 할당받는데 이는 이미 yaml파일에 지정된 값입니다. 사용자가 Dataset의 크기를 고려해 수정이 가능하며 이번 과제에서는 10으로 설정하였고 step 10마다 기록 및 평가를 진행합니다.
→ 정리하자면 val 평가가 종료되면 step, epoch마다 최고의 정확도를 가질때의 weight저장과 통계지표 csv파일, heatmap을 기록하고 저장하게 됩니다.
2-3. 학습 결과 시각화
csv파일 통계
Buster
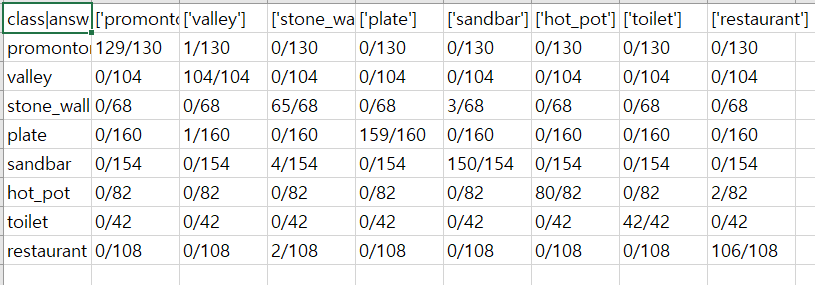
Jo
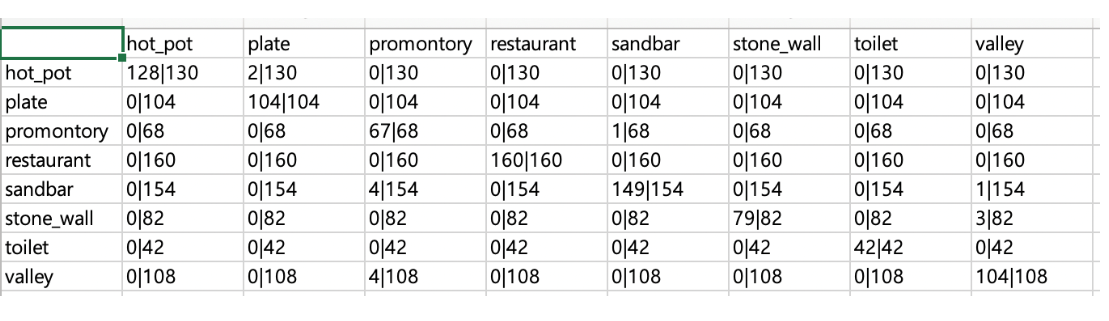
-
첫 번째 시각화 방법으로 콤마(‘,’)를 통해 셀을 나누는 csv파일을 통해 카테고리 별 정확도에 대한 수치를 나타내었습니다.
def record_output(self, answer_data, epoch, step):
...
index_list = [str('') for i in range(0, self.num_class)]
for y in range(0, self.num_class):
category_str += f"{self.label_index[str(y)][0]},"
# category_str -> csv에 작성할 문자열 값
index_list[y] = self.label_index[str(y)][0]
for x in range(0, self.num_class):
category_str += f"{answer_data[y][x]}/{each_val_sum[y]} ," # 정확도를 분수형태로 넣어줌
# 해당 카테고리 중 맞은 정답 갯수 / 해당 카테고리 중 검증 데이터 총 갯수
data_for_record[y][x] = (round(answer_data[y][x] / each_val_sum[y], 2)) * 100
# heatmap에 표현할
category_str += "\n"
output_file.write(category_str)
...
⇒ 다른 프로그래밍 언어의 파일 쓰기 형식처럼 ( 예를 들어 C언어의 fwrite같이 ) 작성할 스크립트를 담은 문자열 변수를 open으로 선언한 csv파일에 write해주는 형식으로 csv를 작성해주면 통계용 파일이 완성됩니다.
heatmap 이미지 통계
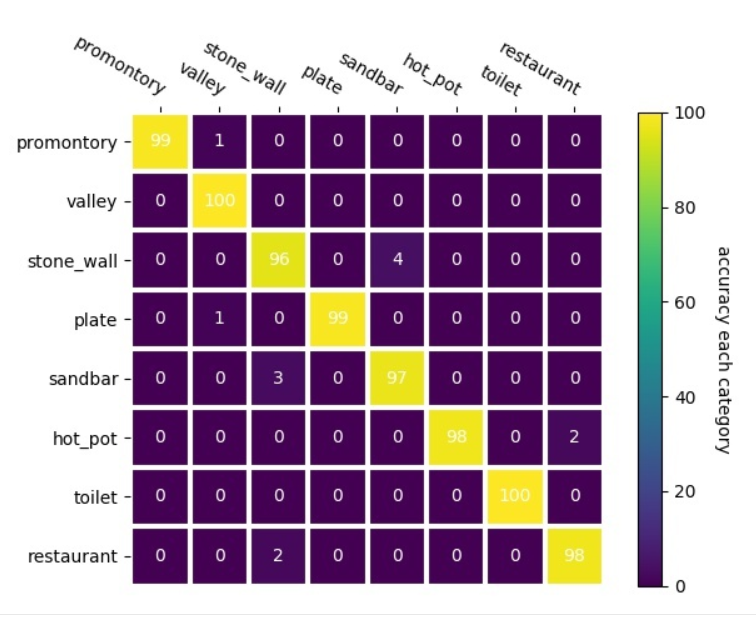
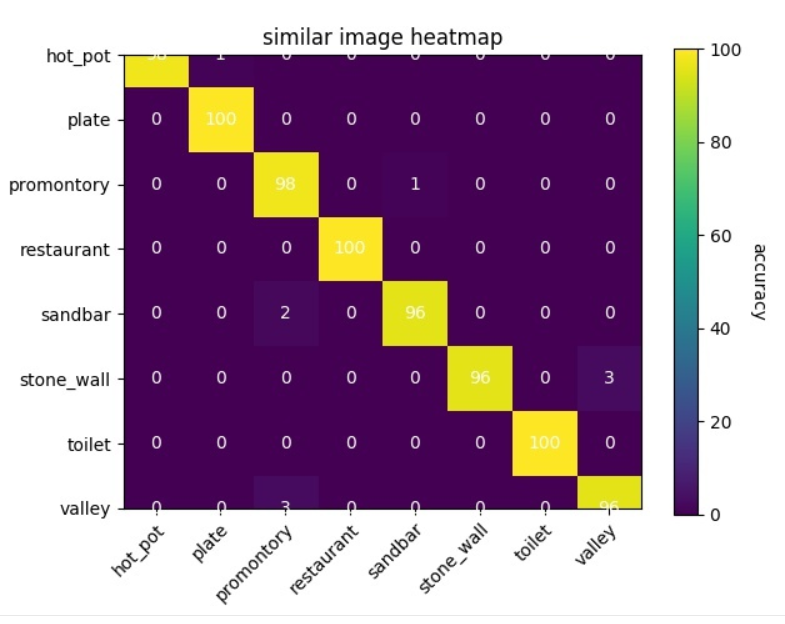
- ( ※ 각각 Buster(좌)와 Jo(우)의 각 카테고리 별 평가용 데이터에 따른 정확도를 히트맵으로 시각화한 결과를 보여줍니다. )
-
두 번째 방법으로 기존에 사용하던 matplotlib을 이용하여 각 카테고리 별 정확도 퍼센트를 heatmap으로 표현해 기록하였습니다.
def make_heatmap(self, index_list, data_for_record, epoch, step):
'''히트맵으로 csv파일에 기록된 정확도를 단순 확률로 간략화해서 보여줌'''
fig, ax = plt.subplots() # 그래프를 불러오는 함수
if not ax:
ax = plt.gca()
im = ax.imshow(data_for_record)
color_bar = ax.figure.colorbar(im, ax=ax)
color_bar.ax.set_ylabel("accuracy each category", rotation=-90, va="bottom")
# title에 해당하는 부분 작성
...
for i in range(len(index_list)):
for j in range(len(index_list)):
text = ax.text(j, i, data_for_record[i][j],
ha="center", va="center", color="w") # append text to ax
# heatmap그래프 각 칸에 들어갈 확률 값을 채움
...
⇒ 위에 csv 파일에 write할 때와 비슷하게 plt의 내장 함수를 통해 불러온 heatmap 중 그래프 형식의 공간에 text를 채워넣는 형식으로 구동되게 설정해 놓았습니다.
3. Conclusion
- 전체 학습과 분류기 부분만 학습 두 가지 옵션을 선택 가능하며 분류기 학습만 진행시 GPU를 사용하지 않더라도 일반적인 densenet모델을 통한 이미지 처리 학습보다 더 빠른 속도의 학습이 이뤄지는 것을 알수 있습니다.
- 다른 카테고리 분류 상황에서도 분류기 부분만 따로 학습해 필요할 때마다 적절한 가중치 파일 선택으로 여러 상황에 대처할수 있게 설계되었습니다. 기존에 ImageNet 으로 학습되어 general 한 특징을 추출할수 있는 원본 가중치에서 안에 dictionary 형태로 저장된 분류기 부분만 바꿔서 동작시키면 원하는 카테고리에 맞게 분류를 해줄수 있게 됩니다.
: 결론적으로, 위에 장점을 기반으로 두 학습기 모두 테스트 학습에 대한 평균 정확도가 90% 중후반을 보여주면서 문제 없이 학습이 이루어 지는 것을 확인 할수 있었습니다.
번외 : 개발 도중의 시행착오
-
소통 부재로 yaml파일 tester파일의 분리

→ Trainer를 분리해서 작성하는건 사전에 어느정도 이야기가 되고 예측가능한 상황이었지만 Trainer에서 호출할 yaml파일의 속성 값들도 따로 작성하며 트레이닝의 테스트를 진행해 이후 통합하기 어려울 정도로 각 yaml의 속성 관계가 복잡해지게 되었습니다.
결국 yaml은 trainer코드에 대한 전면적인 수정을 해야해서 분리되는 방향으로 결정됬지만 tester같은 경우는 큰 변화가 필요없어서 처음 주어진 코드를 기반으로 서로 추가된 기능들을 충돌없이 따로 반영하는 것을 통해 하나로 통합되었습니다.
-
약속되지 않은 모델 변경 및 파일 추가
→ 위에 소통 문제와 연계해 처음 densenet 원본 모델 클래스가 있는 modeling_densenet.py파일을 수정할려고 했었던 것이나 트레이너를 위한 개별 파일을 추가 혹은 삭제(특히 시스템 파일) 하는 것 등 사전에 협의되지 않은 변경 사항으로 다른 트레이너 코드에 영향을 줄수 있는 부분을 다시 정리하는 것도 하나의 홍역이었던거 같습니다.
github를 통해 conflict나는 부분을 대조해보기도 하고 서로의 변경사항을 각자 코드에 추가해 맞춰줌으로써 해결되었지만 다른 협업자의 코드에 영향을 줄수있는 부분의 수정 등을 신중히 접근해야 한다는 것을 깨닫게 해주는 작업이기도 하였습니다.
-
예외 처리의 중요성
→ 워크스테이션에서의 트레이닝 도중 출력된 divide by zero에러와 프로세스가 kill되는 문제에서 후자의 경우는 코드를 잘못 타이핑해 CPU와 GPU에 데이터가 따로 노는 것이 원인이었지만 나머지 divide by zero같은 경우 예외 처리의 문제로 판명되었습니다.
시스템 파일 같은 이미지 외에 필요 파일들의 존재 등을 고려하지 않은 문제 때문에 코드 1줄이면 해결될 문제가 이틀 가까이를 소모하게 만들었습니다.
-
다른 분야의 협업자 배려 + default값 설정
→ 기존 yaml을 서로가 다른 트레이너를 자기 환경에서 테스트할 때나 일반적인 자기 환경 내의 테스트 상황에서도 편하게 테스트하기 위한 용도로 값이 설정되어 있어서 워크스테이션 동작 시 호환이 안되는 문제가 발생하기도 하였습니다.
만약 AI쪽은 잘 모르는 사람과 협업을 할 경우 default값을 신중히 세팅하거나 협업자의 테스트 환경에 대한 소통을 진행하여 해당 문제의 유발을 최소화하도록 하는 것도 중요한 사안이라는 점을 알게되었습니다.
Reference