
Abstract
AIVORY는 너드팩토리에서 개발한 인공지능 추천 검색 솔루션입니다. 현재 구글, 네이버와 같이 이름만 들어도 알 수 있는 검색엔진들은 유사한 이미지를 검색할 수 있는 서비스를 제공하고 있습니다. AIVORY에도 그런 기능이 필요하다고 생각해서 유사 이미지 검색 기능을 추가하기로 했습니다. 동시에 대형 검색엔진들과 달리 폐쇄적인 환경에 작동하는 제품의 특성을 고려해야 했습니다. 이 글에서는 유사 이미지 검색 기능을 구현한 과정에 대해 다루고 있습니다.
유사 이미지 검색 구현 과정
유사 이미지 검색 개발 환경은 아래와 같습니다.
- 데이터: ShutterStock의 회사 계정 라이센스 내역 중 일부(930여 장)
- 네트워크 모델: ImageNet으로 미리 학습된 ResNet
- 웹 프레임워크: Flask
네트워크 모델 정하기
저희는 유사 이미지 검색에 성능이 이미 확인된 네트워크 모델을 사용하고자 했습니다. 그래서 ImageNet이라는 이미지 데이터 셋을 분류하는 대회인 ILSVRC에서 우승한 모델들 중에서 정하기로 했습니다. 후보로 선정된 모델로는 GoogLeNet(2014년 우승 모델), ResNet(2015년 우승 모델), SENet(2017년 우승 모델)이 있었습니다.
위 모델들을 비교할 지표로 삼은 것은 accuracy(정확도)와 inference time이었습니다. 여기서 inference time은 이미지 하나가 입력으로 들어와서 판단되기까지 걸리는 시간을 말합니다. 쉽게 생각하면 이미지 하나를 분류하는 데 걸리는 시간이라 할 수 있습니다. 후보 모델 모두 epoch(횟수)와 learnig rate(학습률)를 동일하게 트레이닝한 결과 아래의 표와 같은 결과를 얻었습니다.
| GoogLeNet | ResNet | SENet |
| accuracy(%) | 93.8 | 94.8 | 94.3 |
| inference time(sec) | 0.004 | 0.002 | 0.003 |
위 결과는 실행환경에 따라 차이가 있을 수 있습니다.
이 중에서 가장 정확도가 높고 inference time이 짧은 ResNet이 최종적으로 선택되었습니다.
ResNet
ResNet이 ILSVRC에 출전하기 전부터 분류 성능을 높이기 위해 층이 점점 더 깊은 모델들이 만들어지고 있었습니다. 하지만 층이 깊어질수록 생기는 문제점도 있었습니다. 그중 gradient vanishing은 역전파 되는 gradient가 중간에 사라져서 학습이 잘되지 않는 문제점입니다. 그래서 ResNet을 개발한 팀은 gradient가 잘 흐를 수 있도록 일종의 지름길을 만들어 주자는 생각을 하게 되었고, 그 결과 아래와 같은 구조를 가지게 된 것입니다.
 원본 출처: https://arxiv.org/pdf/1512.03385.pdf (가독성을 위해 ResNet 구조 이미지를 회전시켰습니다.)
원본 출처: https://arxiv.org/pdf/1512.03385.pdf (가독성을 위해 ResNet 구조 이미지를 회전시켰습니다.)
지름길이 존재하는 곳을 자세히 살펴보면,
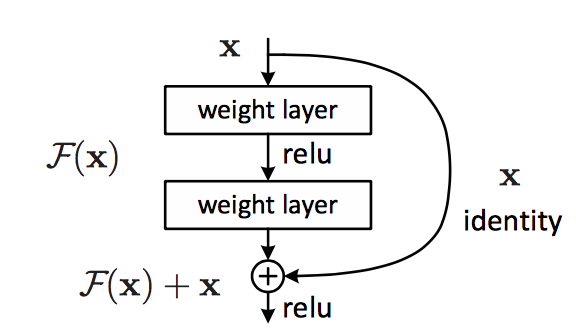
위와 같은 형태의 Residual block을 볼 수 있습니다.
이러한 구조 덕분에 ResNet은 층의 깊이에 비해 parameter 수가 많지 않고, layer를 건너뛰며 연결이 되기 때문에 학습이 간단하게 이뤄질 수 있어서 층이 깊은 네트워크의 장점을 잘 살릴 수 있었습니다.
같은 물체 찾기
ImageNet으로 학습시킨 ResNet이 잘 학습되었는지 확인하기 위해 유사 이미지 검색의 전단계로 같은 물체 찾기를 진행했습니다.
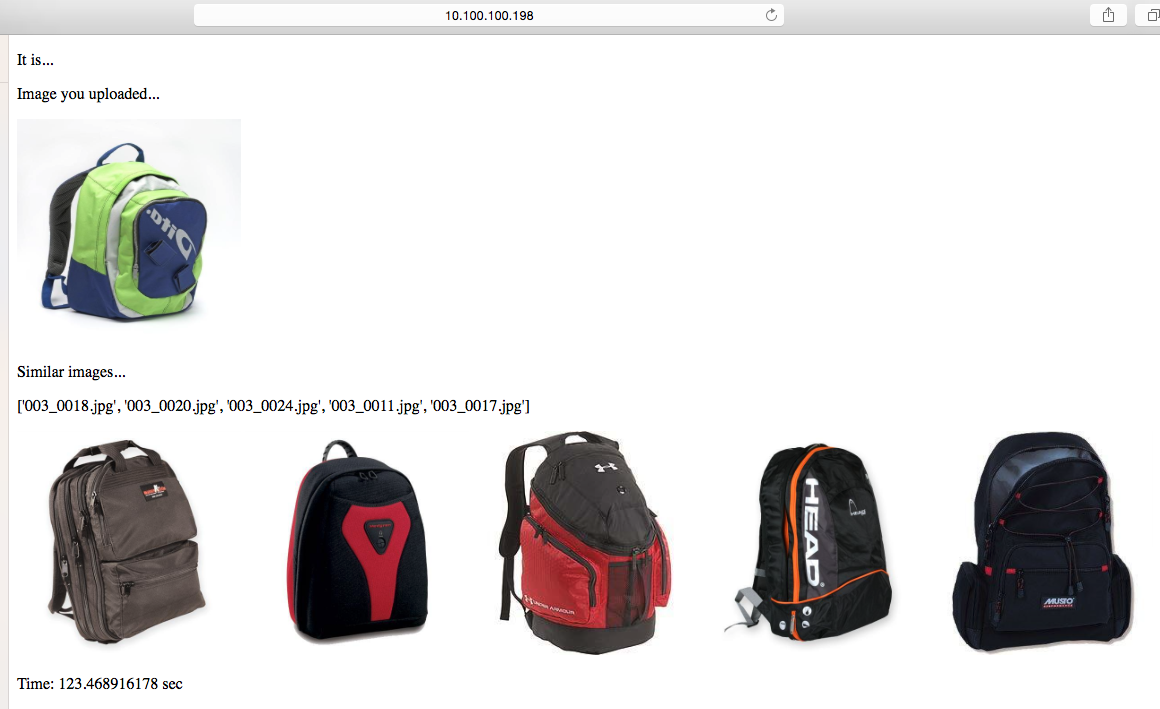 업로드한 이미지(좌측 상단) / 같은 물체로 판단된 이미지들(하단)
업로드한 이미지(좌측 상단) / 같은 물체로 판단된 이미지들(하단)
가방 사진을 넣으면 가방들이 나오고,
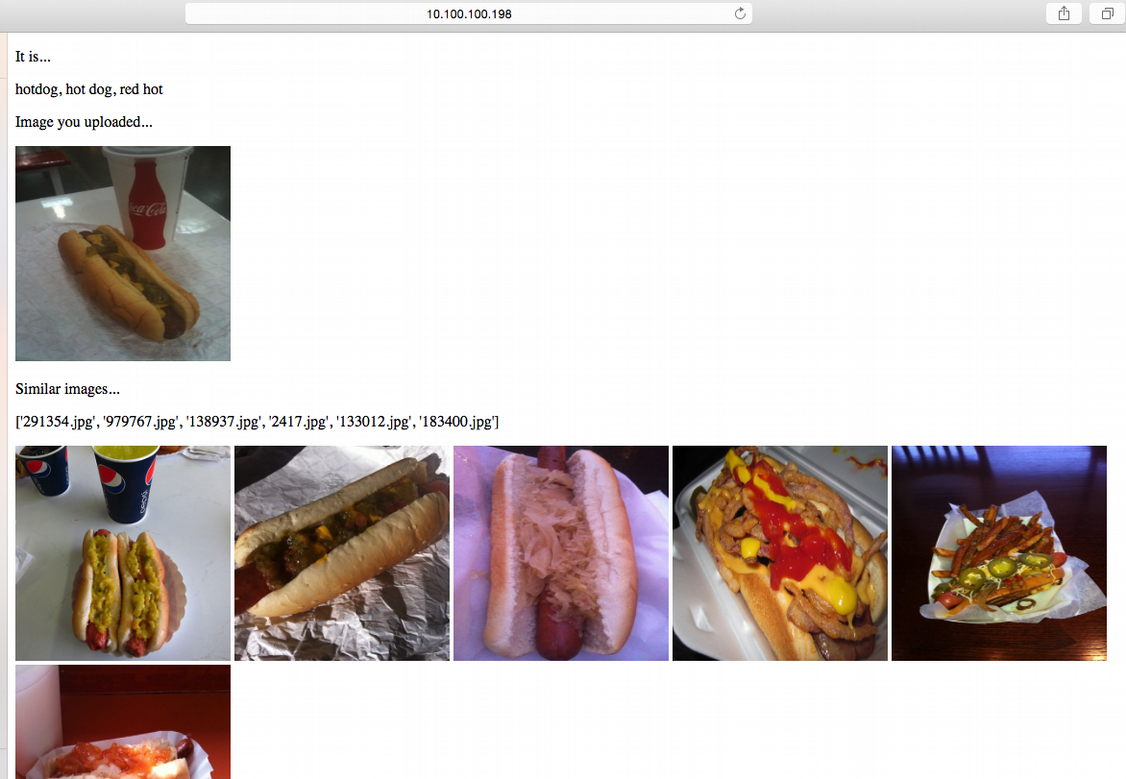 업로드한 이미지(좌측 상단) / 같은 물체로 판단된 이미지들(하단)
업로드한 이미지(좌측 상단) / 같은 물체로 판단된 이미지들(하단)
핫도그 사진을 넣으면 핫도그들이 나왔습니다. 위 결과를 통해 ResNet이 잘 학습되었음을 알 수 있었습니다.
Feature 추출하기
하지만 위의 ResNet을 유사 이미지 검색에 그대로 사용할 수는 없었습니다. ImageNet을 학습했기에 결과도 ImageNet에 존재하는 클래스들에 맞춰서 나오기 때문이었습니다. 그래서 각 이미지들이 ResNet에서 output에 도달하기 전 특정 지점에서 feature를 추출하는 작업이 필요했습니다. 여기서 feature는 이미지의 특징을 나타내는 벡터입니다. feature를 추출하는 위치는 벡터 연산량과 유사 이미지 정확도를 고려하여 선정했습니다.
벡터 저장 방식의 변화
feature로 추출한 벡터를 저장하기 위해 처음에는 ElasticSearch를 사용했습니다. 초기에는 데이터로 쓸 이미지를 받아오는 일과 이미지의 feature를 추출하는 일을 병행하고 있었습니다. 그래서 feature 추출까지 완료된 이미지 수가 적어서 ElasticSearch로 벡터를 저장하고 불러오는 데에 문제가 없었습니다. 하지만 feature 추출이 완료된 이미지 수가 증가하면서 저장해야 하는 벡터가 늘어나자 ElasticSearch가 강제 종료되는 문제점이 발생했습니다. 그 후 안정적으로 벡터를 저장하고 불러오기 위해 파일 입출력 방식으로 저장 방식을 바꾸게 되었습니다.
초기 결과 및 문제 해결 과정
처음 시도한 유사 이미지 검색 결과는 아래와 같았습니다.
 90장 넣었을 때
90장 넣었을 때
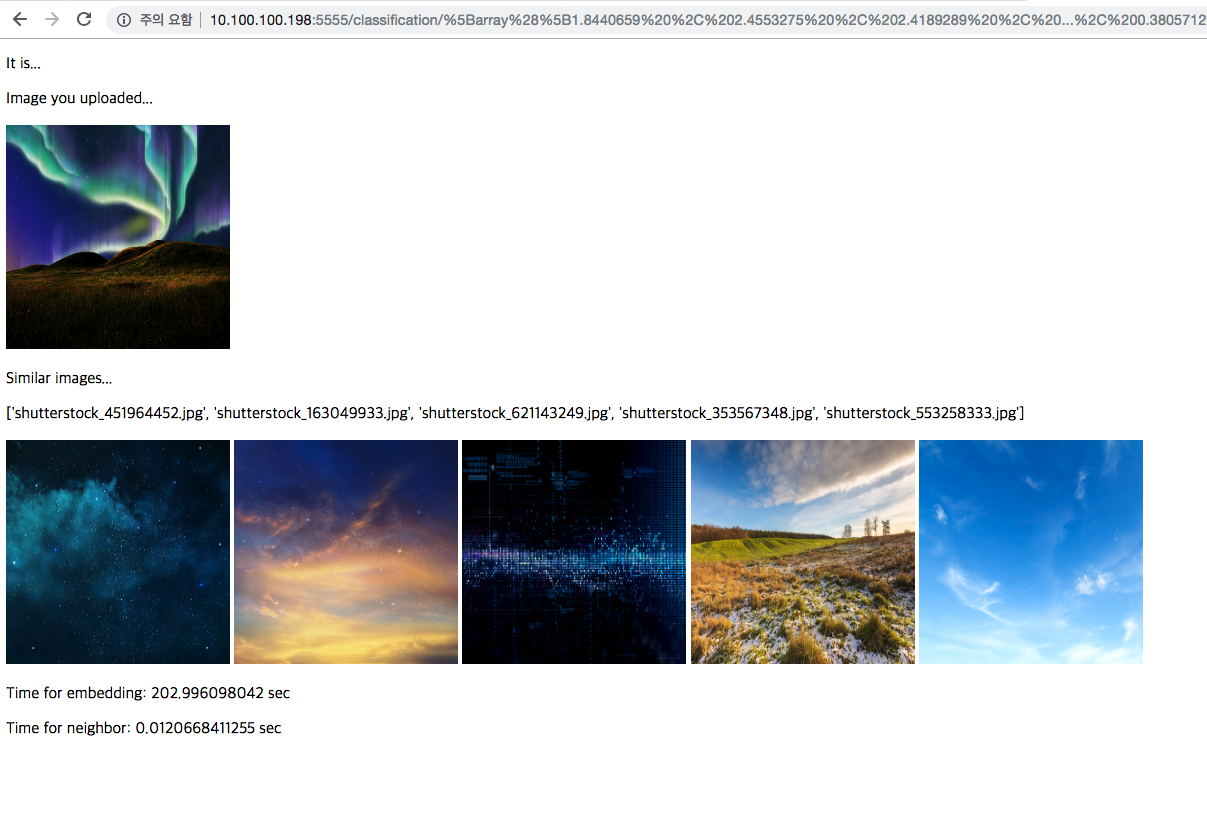 450장 넣었을 때
450장 넣었을 때
 900장 넣었을 때
900장 넣었을 때
업로드한 이미지와 유사한 이미지들을 잘 띄워줬지만, 여기에는 치명적인 문제점이 있었습니다.
바로 시간입니다. 아래의 표와 같이 파일 수가 늘어날수록 걸린 시간도 늘어났습니다.
| 파일 수(개) | 걸린 시간(sec) |
| 90 | 9 |
| 450 | 200 |
| 900 | 300 |
위 결과는 실행환경에 따라 차이가 있을 수 있습니다.
알고리즘
앞서 본 화면을 보여주기까지의 알고리즘은 이러합니다.
- 데이터 셋의 이미지 파일 전체를 불러와 업로드한 이미지와의 벡터 거리를 각각 비교
- 벡터 거리가 가까운 순서대로 상위 10%를 유사 이미지 후보로 선정
- 후보들과 업로드한 이미지의 키워드를 비교
- 키워드가 일치하는 수가 많은 순대로 5개가 최종적으로 유사 이미지
여기서 시간이 많이 걸리는 부분은, 벡터 거리 비교 부분이었습니다.
업로드한 이미지를 데이터베이스에 있는 모든 이미지와 벡터 거리를 비교하는 것이 걸린 시간의 대부분을 차지했습니다.
개선된 알고리즘
어떻게 하면 시간을 줄일 수 있을까 고민하던 중, 벡터 거리가 가깝다면 벡터를 모두 더한 값도 비슷하지 않을까 생각했습니다. 그래서 아래와 같은 알고리즘을 구현했습니다.
- 각 이미지별로 벡터를 합산한 후 업로드한 이미지의 벡터 총합과 비교
- 벡터 총합이 유사한 순서대로 상위 10%를 유사 이미지 1차 후보로 선정
- 1차 후보들과 업로드한 이미지 간의 벡터 거리 비교
- 벡터 거리가 가까운 순서대로 1차 후보의 2/3을 2차 후보로 선정
- 2차 후보들과 업로드한 이미지의 키워드를 비교
- 키워드가 일치하는 수가 많은 순서대로 6개가 최종적으로 유사 이미지
이 알고리즘을 적용한 결과, 이전에 비해 전체 이미지의 10%만 벡터 거리를 비교하여 시간이 대폭 절약되었습니다.
Result

이랬던 것이
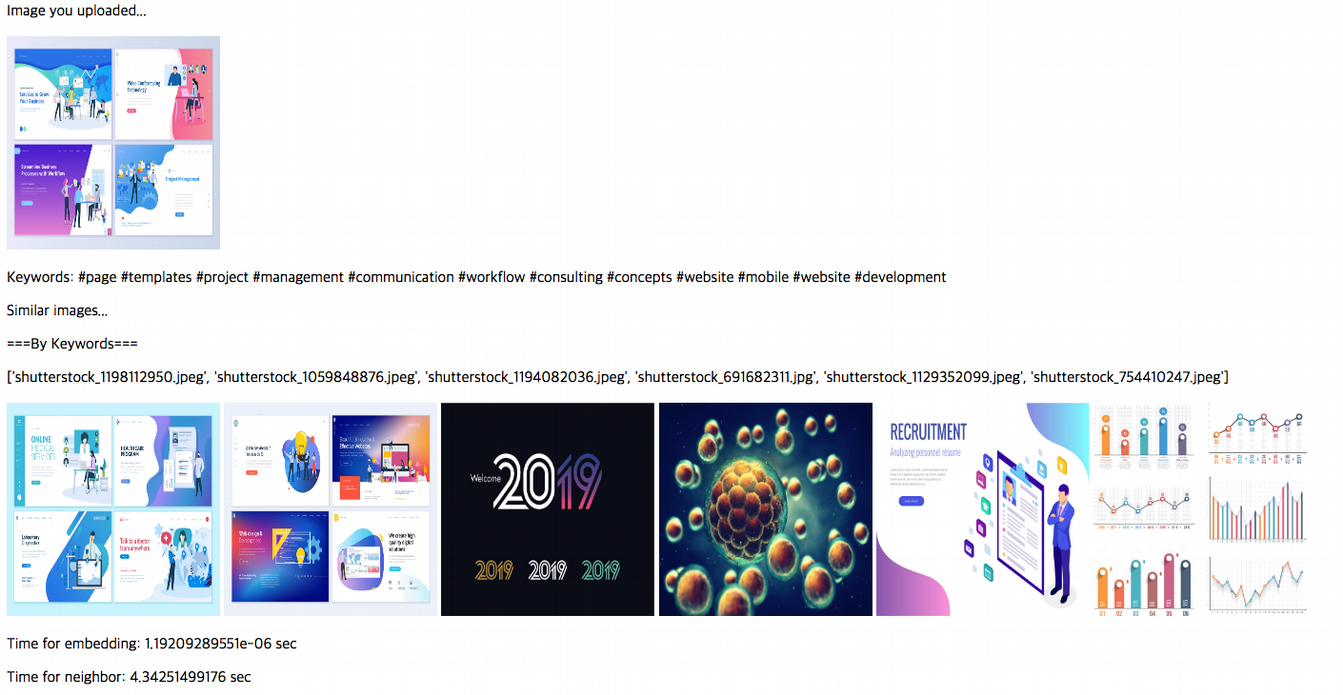
이렇게 바뀌었습니다.
유사한 이미지 수로만 보면 더 안 좋아졌다고 느낄 수 있습니다. 하지만 여기서 중요한 건 걸린 시간이 300초에서 4초로 대폭 감소했다는 점입니다. 눈썰미가 좋은 분들은 위 결과 화면에서 걸린 시간을 발견하셨을 거라 생각합니다.
Conclusion
이 글에서 소개한 유사 이미지 검색 기능은 아직 개발 단계이고, 계속 보완을 해나가는 중입니다. 구체적으로는 위의 결과 화면에서 보셨듯이 시간을 단축하면서 정확도가 다소 낮아졌다는 문제점이 남아있고 이를 해결하기 위한 방안을 지속적으로 찾고 있습니다.
Reference
[1] Deep Residual Learning for Image Recognition
[2] 딥 러닝을 이용한 영상 인식 기술 동향 -ILSVRC 사례를 중심으로