목차
- 대표적인 기계학습적 추천알고리즘 분석
- 사례를 통한 심층학습적 추천알고리즘 분석
- 언급한 추천알고리즘을 솔루션으로 개발할 때의 문제점 발견
- 문제점의 해결 방법
- AIVORY의 전체적인 추천 방법
요약
과거에는 TV의 뉴스 혹은 신문과 같은 단방향적 정보의 흐름에 의존하며 어떠한 매체에 의해 전달되는 정보를 개인이 소비를 해왔습니다. 하지만 PC가 점점 보급이 되며 개인도 정보를 생성하여 다수에게 제공할 수 있게 되고 제공, 소비되는 정보의 양이 점점 많아졌습니다.
2010년 스마트폰이 시장에 출시되면서 사람들은 어디에서나 인터넷에 접속할 수 있게 되었으며 무선 인터넷이 급진적으로 퍼지게 됨과 시너지효과를 내어 현재 2019년에는 전세계 어디에서든 인터넷을 접속할 수 있는 세상이 만들어졌습니다.
그리하여 사람들은 어디에서나 정보를 제공받을 수 있으며 제공할 수 있게 되었습니다. 이로 인해 셀 수 없을 만큼의 정보가 홍수처럼 생산되고 있습니다. 하지만 이 중에는 필요한 정보도 있지만 개인들에게는 불필요하거나 관심 밖의 정보가 제공되기도 하면서 개인들은 필요한 정보만을 골라서 소비를 하고 싶어허는 욕구가 증가하게 되었습니다.
현재 구글, 네이버, 카카오 등 거대 공룡기업들은 그들이 가지고 있는 정보를 제공함에 있어 개인화 맞춤형 컨텐츠 제공을 함으로써 개인들을 그들의 서비스에 지속적으로 머무르게 할 수 있습니다. 이를 통해 개인들이 생산하는 데이터를 더 많이 모을 수 있으며 추천을 할 수 있는 더 많은 데이터를 모을 수 있습니다. 개인들에 의해 생산, 제공된 데이터를 통해 다시 더 좋은 추천 알고리즘을 제공함으로써 이는 선순환 구조를 이루어 데이터의 빈익빈 부익부 현상이 이루어질 것이라고 많은 사람들이 생각하고 있습니다.
위의 글을 다시 정리하면 다음과 같습니다.
- 사용자들을 서비스에 머무르게 할 수 있게 합니다.
- 서비스에 머무르면서 사용자들을 정보를 다시 재생산합니다.
- 재생산된 정보들을 이용하여 서비스 제공자는 정확한 추천알고리즘을 제공합니다.
- 1~3를 반복하면서 서비스의 크기를 키울 수 있습니다.
정리한 항목을 토대로 하였을 때 추천알고리즘을 서비스 이용자에게 제공하는 것은 선택이 아닌 필수가 되었습니다.
추천알고리즘을 구현하는데 있어서 어떠한 알고리즘이 현재까지 연구되었는지 알아보며 문제점을 발굴하고 이를 해결하여 너드팩토리에서 개발한 AIVORY에 어떻게 적용이 되었는지 알아보겠습니다.
대표적인 기계학습적 추천알고리즘
먼저 구글에 머신러닝 추천알고리즘이라고 검색을 하면 Collaborative Filtering(이하 협업 필터링)이라는 것을 흔하게 볼 수 있습니다. 위키피디아에서 협업 필터링은 찾아보면 다음과 같이 정의되어 있습니다. 협업 필터링은 많은 사용자들로 부터 얻은 기호정보에 따라 사용자들의 관심사들을 자동적으로 예측해주는 방법입니다. 이 방법은 대표적으로 아마존에서 사용하고 있습니다. 협업 필터링은 일반적으로 크게 2가지로 분류됩니다. 그리고 2가지로 분류된 협업 필터링은 2가지 단계로 운영됩니다.
-
아이템 기반, 유저 기반 협업 필터링
- 정보를 추천하고자 하는 고객과 비슷한 고객을 찾는다.
- 정보를 추천하고자 하는 고객의 행동을 예측하기 위해 비슷하다고 생각되는 고객의 행동을 수치화 한다.
-
컨텐츠 유사도 기반의 협업 필터링
- 아이템간의 상관관계를 결정하는 아이템 행렬을 만든다.
- 행렬을 이용하여 정보를 추천하고자 하는 고객과의 상관관계를 유추한다.
이렇게 이론적으로 설명하면 이해하기 어렵기 때문에 사례를 들어가며 설명하겠습니다.
유저 기반 협업 필터링
유저 기반의 협업 필터링과 아이템 기반의 협업 필터링은 거의 같다고 할 정도로 유사하기에 유저 기반의 협업필터링은 먼저 보여드린 후 아이템 기반 협업 필터링을 설명하겠습니다.
먼저 $x$, $y$, $z$라는 세 명의 유저가 있으며 $a$, $b$, $c$, $d$라는 네가지 상품이 있다고 하겠습니다. 이 세 사람이 네 상품을 구매한 이력이 다음과 같이 있습니다.
1은 구매를 했고 0은 구매를 하지 않은 것 입니다.
위의 구매이력을 각 유저들의 특징이라고 생각하면 아래와 같이 각 유저들을 행렬로 정의할 수 있습니다.
\(x = [0, 1, 0, 1]\\
y = [0, 1, 1, 1]\\
z = [1, 0, 1, 0]\)
각 유서들의 특성을 이용하여 유저들 간의 상관관계를 코사인 유사도를 통해 유저 유사도 행렬을 구하면 다음과 같습니다.
|
x |
y |
z |
| x |
1 |
0.82 |
0 |
| y |
0.82 |
1 |
0.2 |
| z |
0 |
0.2 |
1 |
위에서 구한 유저 유사도 행렬과 구매이력 행렬을 곱 연산하면 아이템에 대한 유저들의 선호도 행렬이 아래와 같이 나오게 됩니다.
|
a |
b |
c |
d |
| x |
0 |
1.82 |
0.82 |
1.82 |
| y |
0.2 |
1.82 |
1.2 |
1.82 |
| z |
1 |
0.2 |
1.2 |
0.2 |
선호도 행렬을 의미적으로 해석하자면 다음과 같습니다. 유저 $x$는 아이템 $a$에 대한 선호도는 0이며 $c$에 대한 선호도는 0.82라고 해석할 수 있습니다. 만약 구한 선호도 행렬과 구매 이력 행렬을 이용하여 유저 $x$에게 상품을 추천한다면 $c$를 추천할 수 있습니다. 이미 $b, d$는 구매를 하였기 때문에 추천을 하지 않으며 그 다음 가장 선호도 값이 높은 $c$를 추천하는 것입니다.
아이템 기반의 협업 필터링
위에서 언급했듯이 아이템 기반의 협업 필터링은 유저 기반의 협업 필터링과 같은 흐름을 갖습니다. 하지만 차이점은 하나 존재합니다. 위의 유저 기반의 협업 필터링의 경우 유저 $x, y, z$에 대해서 특성을 만들었지만 아이템 기반의 협업 필터링에서는 아이템 $a, b, c, d$에 대해서 특성을 구합니다. 그 외에는 같은 흐름을 가집니다.
이것은 수학적으로는 정확히 같은 의미를 가지지만 해석적으로는 다음과 같습니다. 아이템 기반의 협업 필터링은 유저에 대한 아이템의 선호를 구하는 것이며, 유저 기반의 협업 필터링은 아이템에 대한 유저의 선호를 구하는 것입니다.
컨텐츠 유사도 기반의 협업 필터링
컨텐츠 유사도 기반의 협업 필터링은 위에서 언급한 유저 기반, 아이템 기반의 협업 필터링과 전혀 다릅니다. 위에서는 구매이력을 이용하여 유저들간 혹은 아이템간의 유사도를 측정하였지만 이 협업 필터링의 경우에는 컨텐츠 그 자체의 특성 유사도를 이용합니다.
현재 상영작인 8개의 영화를 유저에게 추천한다고 가정합니다.

영화 자체의 특성을 만드는데는 여러가지 요소들이 있습니다. 주연배우, 줄거리, 장르, 감독 등이 될 수 있습니다. 이 글에서는 장르를 예로 추천알고리즘을 만들어보겠습니다.
위의 현재 상영작인 8개의 영화를 장르로 구별해보면 다음과 같이 분류할 수 있습니다.
{
'느와르': ['신세계', '아수라'],
'코미디': ['완벽한타인', '럭키'],
'로맨스': ['건축학개론', '뷰티인사이드'],
'스릴러': ['곤지암', '악마를 보았다']
}
만약 어떠한 유저가 신세계를 보았으며 최근에 본 영화를 조회하니 느와르 장르의 영화가 다수 분포한다고 하면 현재 상영중인 영화인 아수라를 추천할 수 있습니다.
컨텐츠 유사도 기반의 협업 필터링의 경우 위와 같이 단순 알고리즘적으로 구현을 할 수 있지만 여러 기게학습적, 심층학습적 기법으로 컨텐츠에 대한 특성을 구하여 컨텐츠 기반의 협업 필터링을 구현할 수도 있습니다.
기계학습적 추천 알고리즘의 문제점
기계학습적 추천알고리즘은 데이터에 기반하여 추천알고리즘을 구현한다는데 있어 몇가지 문제점이 있으며 아래와 같이 나열될 수 있습니다.
- 구매 이력, 시청 이력 등이 없는 유저(콜드 유저)에게는 추천을 할 수 없다.
- 구매 이력, 시청 이력 등등을 이용하여 추천을 하기 떄문에 이미 많은 데이터를 확보하고 있어야 한다.
- 많은 데이터를 처리하기 위해 데이터에 비례하는 연산량을 요구한다.
사례를 통한 심층학습적 추천 알고리즘
심층학습적 추천 알고리즘에는 기계학습적 추천 알고리즘과는 달리 굉장히 많은 방법론이 있습니다. 위에서 설명한 기계학습적 추천 알고리즘의 방법론을 차용하여 심층학습을 통해 추천 알고리즘을 구성하는 방법 또한 있기 때문입니다. 방대한 심층학습적 추천 알고리즘을 모두 설명할 수는 없기 때문에 여러분들이 인터넷에서 가장 흔히 그리고 쉽게 접할 수 있는 유투브의 추천 알고리즘에 대해 고찰해보겠습니다.
유투브의 추천 알고리즘은 멀리서 찾지 않아도 됩니다. 구글에 youtube recommendation을 검색하면 논문이 하나 나오게 되는데 제목은 Deep Neural Networks for Youtube Recommendations 입니다.
위의 논문에서 가장 중요한 그림 하나에 대해서 설명을 드리겠습니다.
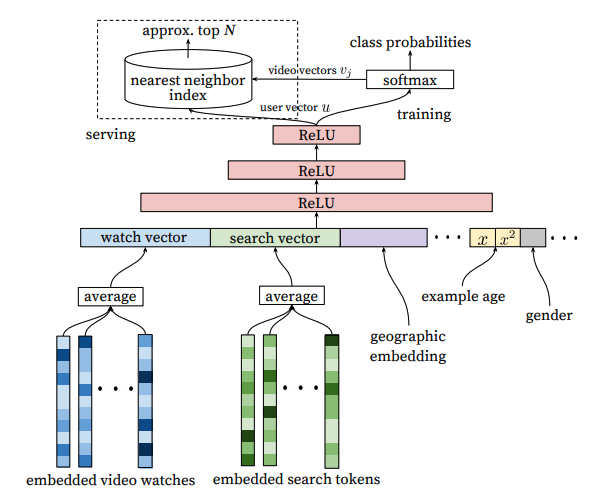
위의 그림을 보면 유저를 어떠한 하나의 벡터형태로 embedding하는 일을 먼저 합니다. 유투브의 추천 알고리즘은 유저의 여러가지 특성을 이용하여 embedding을 합니다. 그림에서 볼 수 있듯이 지금까지 본 비디오, 지금까지 검색한 검색어들, 거주지, 연령대, 성별 등등을 이용합니다. 앞의 특성들을 하나의 벡터로 이어붙이기를 한 후 심층신경망을 통과 시킵니다. 유저의 특성벡터를 심층신경망에 통과시킨 후 class probability를 구하게 되고 이 과정에서 유저들은 서로 의미 있는 $user\ vector\ u$를 가지게 됩니다. 이 의미 있는 유저 벡터들을 특징 공간에 뿌린 후 이를 토대로 nearest neighbot index를 구하고 그 중에 가장 가까운 것을 선택하여 추천하는 방식을 가지고 있습니다.
매우 개략적으로 설명을 하였기 때문에 더 정확하게 알고 싶으시면 논문을 보시는 것을 권유합니다.
심층학습적 추천 알고리즘의 문제점
심층학습적 추천알고리즘은 기계학습적 추천 알고리즘이 가지는 문제점도 가지며 더 치명적인 문제점 또한 가지고 있습니다.
- 구매 이력, 시청 이력 등이 없는 유저(콜드 유저)에게는 그 유저의 특성을 구할 수 없기 때문에 추천을 할 수 없다.
- 매우 방대한 크기의 인공신경망을 학습해야 되기 때문에 기게학습적 추천 알고리즘이 요구하는 데이터보다 훨씬 많은 데이터를 필요로 한다.
- 더 많은 데이터를 처리할 연산량을 요구한다.
- 주기적으로 데이터를 들여다본 후 인공신경망을 업데이트 해주어야 한다.
언급한 추천알고리즘을 솔루션으로 개발할 때의 문제점 발견
위의 기계학습적, 심층학습적 추천 알고리즘의 문제점을 요약하면 아래와 같습니다.
- 구매 이력, 시청 이력 등이 없는 유저의 특성을 구할 수 없기 때문에 추천을 할 수 없다.
- 매우 방대한 크기의 데이터를 보유하고 있어야 한다.
- 방대한 크기의 데이터를 처리할 수 있는 연산량(Computing Power)를 요구한다.
- 주기적으로 데이터를 들어다보며 인공신경망을 업데이트 해주어야 한다.
- 설치를 하는데 있어 손쉬워야 한다.
위의 문제점을 해결하는 새로운 추천 알고리즘 AIVORY
AIVORY는 위의 문제점을 극복하는 인공지능 추천 검색 솔루션입니다. 아래는 위에서 언급한 문제점을 해결하는 방식입니다.
- 유저의 특성을 구할 수 없을 때는 강화학습적 방법론을 이용하여 다수의 유저들이 선호하는 컨텐츠를 추천합니다.
- 솔루션을 제공하는데 있어 고객들의 데이터베이스의 크기가 다 다르며 매우 오래된 데이터들이 존재하는 경우가 많이 존재합니다. 이럴 때에는 가장 최근의 데이터들을 읽은 후 추천을 하는데 사용합니다.
- 서비스, 플랫폼을 제공하는 것이 아니며 고객들이 이미 사용하고 있는 혹은 구매할 서버의 사양에 맞추어야 합니다. 그렇기 때문에 굉장히 복잡한 연산을 하는 심층학습적 방법론은 납품을 진행하는 과정에서 수행되며 그 이외에는 관리자의 행동에 맞추어 학습을 진행합니다. 그 외에는 기계학습적, 알고리즘적 추천 방법을 사용합니다.
- 데이터의 경우는 고객의 데이터이기 때문에 기계학습, 알고리즘의 모델을 주기적으로 업데이트를 할 수 없습니다. 이 또한 관리자의 의도에 맞춥니다. 예를 들면 관리자가 업데이트를 하고 싶을 때 업데이트를 하거나 일주일 마다 한번씩 혹은 한달 마다 한번씩 업데이트를 할 수 있도록 주기를 설정할 수 있는 권한을 부여합니다.
- 설치 하는데 있어 가장 중요한 점은 얼마나 다른 패키지와 의존성을 가지는지 입니다. sklearn과 같은 많은 기계학습 library가 존재하지만 상당 수의 부분을 직접 개발함으로써 다른 패키지와의 의존성을 줄였습니다.
위의 문제점을 해결하면서 AIVORY는 유저에게 다음과 같은 흐름을 가지며 컨텐츠를 추천합니다.
- 기존에 존재하는 데이터를 사용한 Text Embedding
- Text Embedded Vector를 이용한 유저 특성 확립
- 컨텐츠를 추천할 유저를 대표할 수 있는 유저(대표자) 도출
- 대표자와 컨텐츠를 추천할 유저의 패턴 도출 후 추천
Text Embedding
AIVORY에서는 Text Embedding기법으로 Word2Vec을 사용하였습니다. Word2Vec에는 CBOW방법과 Skip-gram 방법이 있습니다. 그 중에서 AIVORY는 Skip-gram 방법을 사용하고 있습니다. Skip-gram 모델은 현재 주어진 단어 하나를 가지고 주위에 등장하는 나머지 몇 가지의 단어들의 등장 여부를 유추하는 것입니다. 이 때 예측하는 단어들의 경우 현재 단어 주위에서 샘플링하는데, ‘가까이 위치해있는 단어일 수록 현재 단어와 관련이 더 많은 단어일 것이다’ 라는 생각을 적용하기 위해 멀리 떨어져있는 단어일수록 낮은 확률로 택하는 방법을 사용합니다. Skip-gram을 수학적으로 표현하면 아래와 같습니다.
\[p(w_o|w_i) = \dfrac{exp(v'^{T}_{w_o}v_{w_i})}{\Sigma{exp(v'^{T}_{w}v_{w_i})}}\]
위의 수식을 해석하면 다음과 같습니다. 단어$w_i$가 등장하였을때 단어 $w_o$가 등장할 확률입니다. 복잡해 보이지만 굉장히 간단한 식입니다. 더 상세한 설명을 얻고 싶으시면 Word2vec을 검색하시면 됩니다.
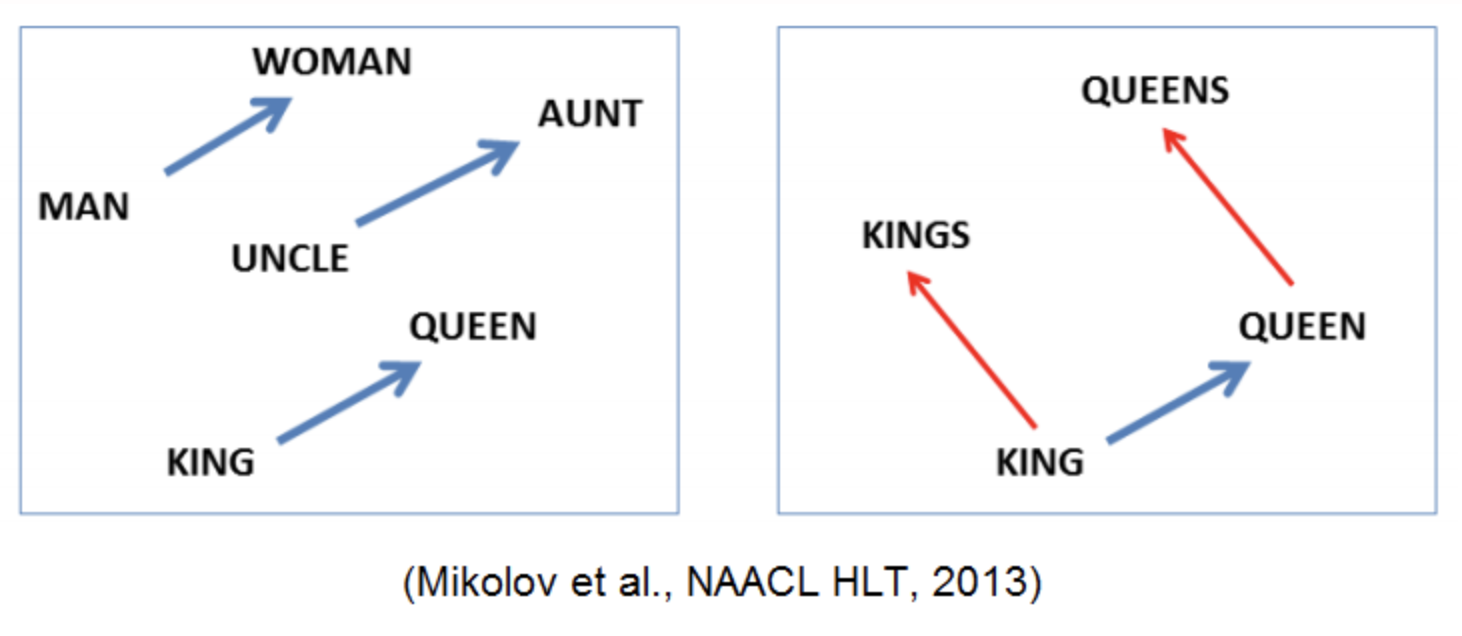
왕에서 남자라는 속성을 제거하고 여자라는 속성을 더하면 여왕이라는 것을 사람은 직관적으로 이해할 수 있습니다. Word2Vec의 방법론을 이용하면 직관으로 얻을 수 있는 결과를 얻을 수 있습니다.
User Embedding
위에서 얻은 Text Embedding 결과를 이용하여 유저를 Embedding할 수 있습니다. 이 방법론은 위의 유투브 추천알고리즘에 착안하여 설계하였습니다. 유저의 특성을 고려하는데 있어서 지금까지 읽었던 비디오를 Embedding하여 평균을 이용합니다. 이것을 Text로 옮겨 다음과 같이 특징을 만듭니다.

추천하고자 하는 유저가 읽은 기사 제목들을 Embedding하고 그 벡터를 평균냅니다. 이 평균 벡터를 유저라고 가정할 수 있습니다.
Find Representative
모든 유저들을 특징 공간에 뿌리면 다음과 같이 뿌려질 수 있습니다.
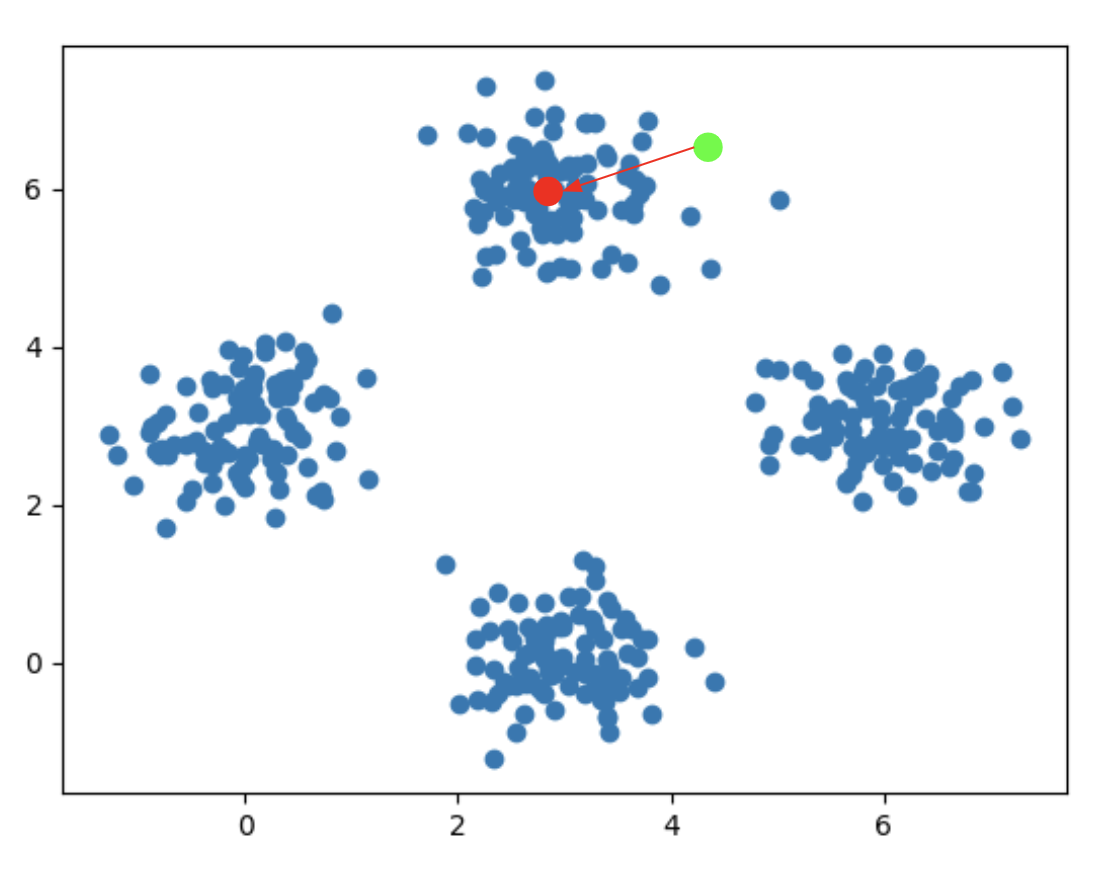
예를 들어 위 특징 공간에서 추천하고자 하는 유저가 초록색 점으로 가정한다면 그 대표자는 빨간색 점으로 생각할 수 있습니다. 만약이 대표자를 찾기 위해서 비지도 분류 알고리즘을 사용할 수 있습니다. 그 중 대표적인 K-means 알고리즘을 생각할 수 있습니다. 하지만 K-means 알고리즘은 분류하고자 하는 클래스의 개수를 사용자가 지정을 해주어야 합니다. 하지만 우리는 유저들이 얼마나 많은 카테고리를 가지고 있는지를 알 수가 없습니다. 이러한 문제점을 해결하기 위해서 자체 개발한 Auto K-means 알고리즘을 이용하여 유저를 비지도적으로 분류하며 그 중점을 찾습니다. 이렇게 찾은 중점과 가장 가까운 유저를 그 군집을 대표하는 대표자라고 할 수 있습니다. 이제 대표자를 찾았으니 대표자와 추천할 유저의 패턴을 찾아 추천을 하게 됩니다.
Find Patterns between User and Representative
예를 들어서 대표자(빨간점)과 추천할 유저(녹색점)이 다음과 같은 글을 읽었으며 추천할 유저에게 컨텐츠를 하나 제시해야한다고 가정하겠습니다.
 대표자와 유저의 동일한 패턴을 찾아본다면 축구 구성원과 축구 성적을 순서대로 보았다는 것을 알 수 있습니다. 여기서 대표자는 다음으로 국가대표 축구 대진표로 대표되는 컨텐츠를 소비했으므로 추천하고자 하는 유저로 국가대표 축구 대진표로 대표되는 컨텐츠를 소비할 것이라고 예상할 수 있습니다. 그래서 컨텐츠들 중 국가대표 축구 대진표로 대표되는 컨텐츠를 찾은 후 추천을 하게 됩니다.
대표자와 유저의 동일한 패턴을 찾아본다면 축구 구성원과 축구 성적을 순서대로 보았다는 것을 알 수 있습니다. 여기서 대표자는 다음으로 국가대표 축구 대진표로 대표되는 컨텐츠를 소비했으므로 추천하고자 하는 유저로 국가대표 축구 대진표로 대표되는 컨텐츠를 소비할 것이라고 예상할 수 있습니다. 그래서 컨텐츠들 중 국가대표 축구 대진표로 대표되는 컨텐츠를 찾은 후 추천을 하게 됩니다.
마치며
이 글은 추천 알고리즘에 대한 기계학습적 방법, 심층학습적 방법을 살펴본 후 솔루션으로 제공하는데 있어 기계학습적, 심층학습적 방법을 그대로 사용하기에는 여러가지 문제점이 있음을 알 수 있었습니다. 하지만 AIVORY는 알고리즘을 자체 개발하여 언급된 문제점을 해결하였으며 기존의 추천 알고리즘들와 궤를 달리하는 새로운 추천 알고리즘을 구성하였습니다.
새로운 추천 알고리즘을 탑재한 인공지능 추천 검색 솔루션 AIVORY에 대해서 더 자세히 알고 싶으시면 링크를 통해 홈페이지로 접속해보세요. 감사합니다.
Reference
[1] Collaborative Filtering
[2] Cosine Similarity
[3] Deep Neural Networks for Youtube Recommendations
[4] Word2Vec
[5] Auto K-means 알고리즘