
Abstract
너드팩토리에서는 매일 아침 한 자리에 모여서 Daily Scrum을 진행하며 서로 계획을 공유하고 피드백하는 시간을 가지는데 Daily Scrum 시간에 직원분들께서 로그 문제로 이야기하시는 것을 들었습니다. 로그가 그냥 파일에 쌓여서 관리가 안 되고 용량은 계속 증가해서 나중에 서버에도 악영향을 끼칠 것이라는 문제였는데 ELK Stack을 활용하면 이 문제를 해결하는 데에 도움이 되겠다는 생각이 들었습니다. 그래서 현재 상황의 문제점들을 구체적으로 파악하고 ELK Stack의 유용한 기능들의 정보를 수집해 로그 관리 시스템을 구축해보았습니다.
로그 관리의 필요성
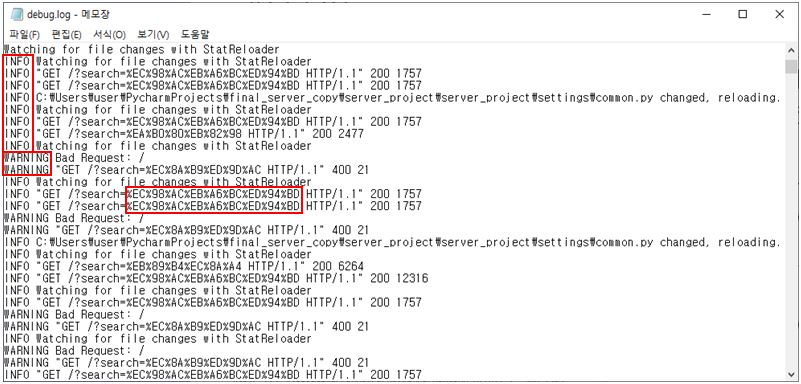 파일에 쌓여있는 로그들
파일에 쌓여있는 로그들
이처럼 로그를 따로 관리하지 않고 파일에 쌓아두기만 한다면 여러 가지 문제점이 발생합니다.
- INFO, WARNING과 같은 log level을 한눈에 파악하기 어려움.
- 검색어의 한글이 퍼센트어로 되어있어서 파악하기 힘들고 검색어 분석 또한 어려움.
- 날짜와 시간에 따른 로그 분석이 어려움.
- 로그가 쌓이다 보면 과거의 로그가 디스크 공간을 너무 많이 차지하게 됨.
이와 같은 문제점들을 해결하기 위해서는 생성되는 로그들을 단순히 파일에 쌓이도록 방치하면 안 되고 로그를 관리해 줄 필요가 있습니다. 이는 로그 분석을 할 때에도 훨씬 효율적이기 때문에 로그 관리 시스템을 구축하면 시스템을 보다 안정적으로 운용할 수 있습니다.
로그 관리 시스템 설계
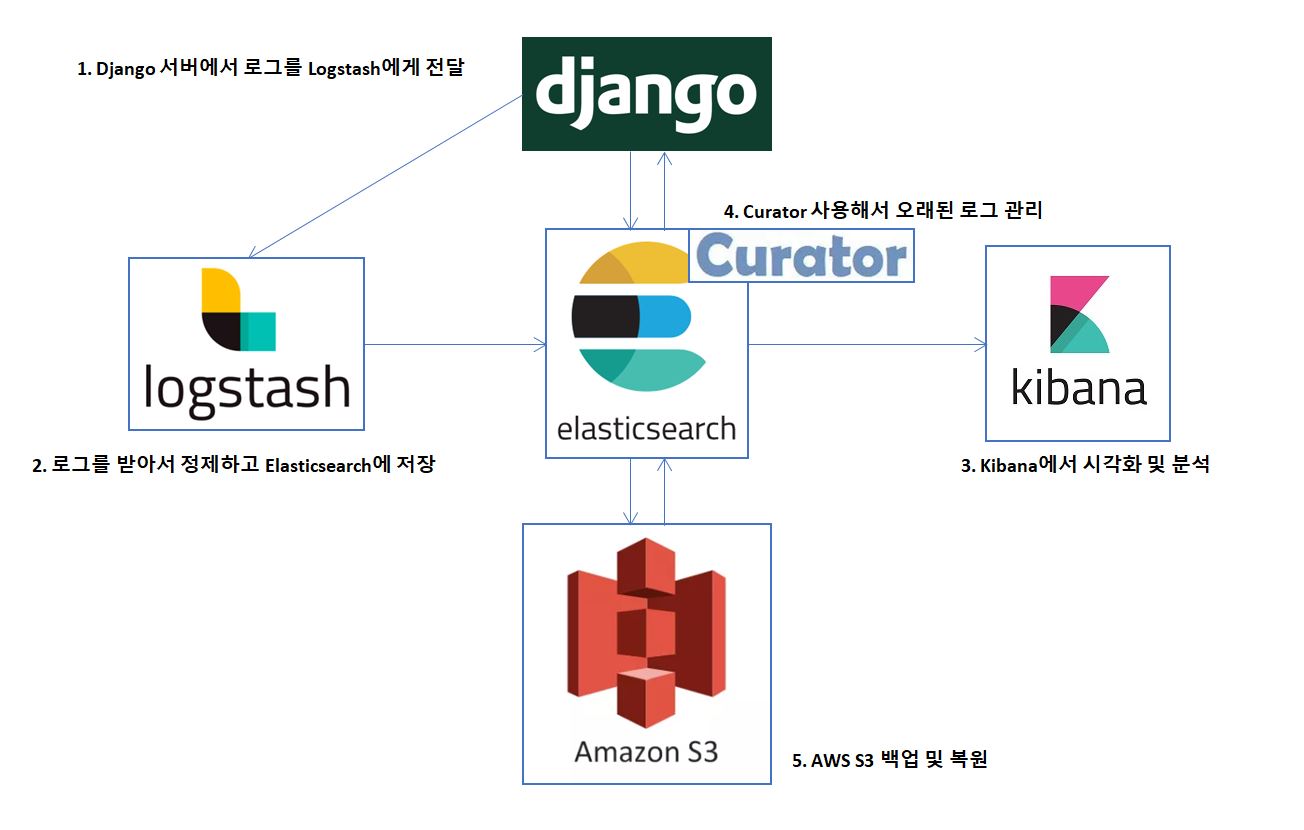 로그 관리 시스템 아키텍쳐
로그 관리 시스템 아키텍쳐
로그 관리 시스템은 다음과 같이 구성하였습니다. Django 서버에서 로그를 Logstash에게 전달하고 Logstash는 로그를 받아서 로그 레코드를 정제해 Elasticsearch에 저장합니다. Kibana에서는 Elasticsearch에 저장되어있는 로그들을 시각화해 다양한 분석이 가능합니다. 그리고 Curator를 사용해서 기간 및 디스크 크기 기준으로 오래된 로그를 자동으로 지워주도록 합니다. 이때 지워버린 로그를 다시 확인해야 할 상황을 대비해 모든 로그는 AWS S3에 백업시켜두고 Curator가 Elasticsearch에서 로그를 지웠더라도 언제든지 AWS S3에서 복원하여 분석할 수 있도록 하였습니다.
- Django 서버에서 로그 생성
Django 디폴트 로그 설정은 Apache와는 다르게 로그가 기록되지 않기 때문에 settings.py파일에서 따로 설정해주어야 합니다. TCP 네트워크 소켓을 통해 Logstash에게 로그 레코드를 전달하도록 설정하였습니다.
# settings.py
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': { # handlers : 로그 레코드로 무슨 작업을 할 것인지 정의
'logstash': {
'level': 'INFO',
'class': 'logstash.TCPLogstashHandler',
'host': 'localhost',
'port': 5959, # Default value: 5959
'version': 1,
},
},
'loggers': { # loggers : 처리해야 할 로그 레코드를 어떤 handler로 전달할지 정의
'django': {
'handlers': ['logstash'], # 로그 레코드를 logstash handler로 전달
},
},
}
- Logstash 설정
logstash를 실행할 때에는 파라미터로 configuration 파일을 넘겨주어야 합니다. configuration 파일을 통해 데이터 변환부터 out하기까지 input, filter, output을 어떻게 구성할지 설정할 수 있습니다.
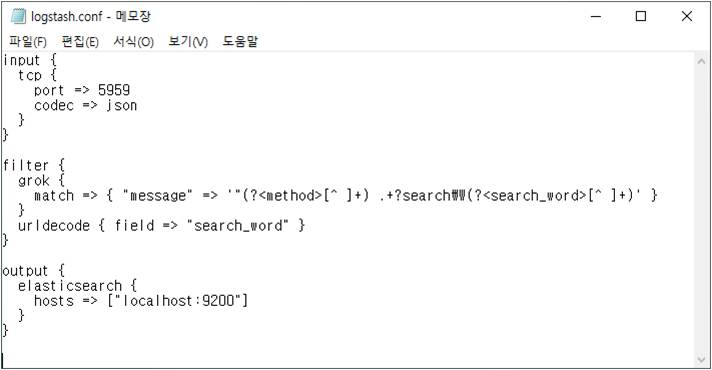 logstash.conf
logstash.conf
TCP 네트워크 소켓을 통해 로그 레코드를 받아 Elastic에서 제공하는 grok필터를 사용하여 method와 검색어를 추출하고 퍼센트어로 되어있는 검색어를 디코딩 해줍니다. 그리고 가공된 데이터를 Elasticsearch로 전달하도록 설정하였습니다.
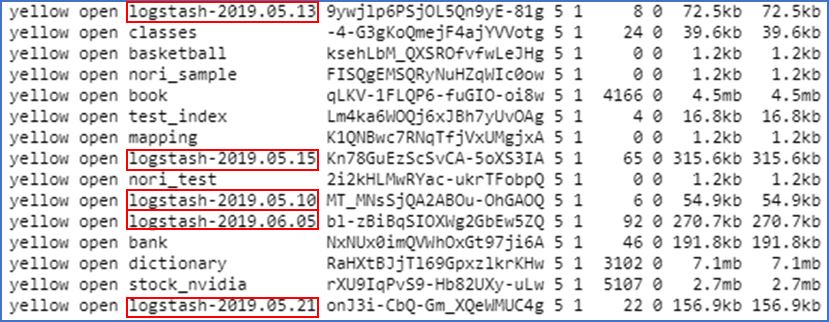 Elasticsearch에 저장된 로그들
Elasticsearch에 저장된 로그들
전달된 로그들은 다음과 같이 ‘logstash-yyyy.mm.dd’로 저장됩니다.
- Kibana 시각화 및 분석
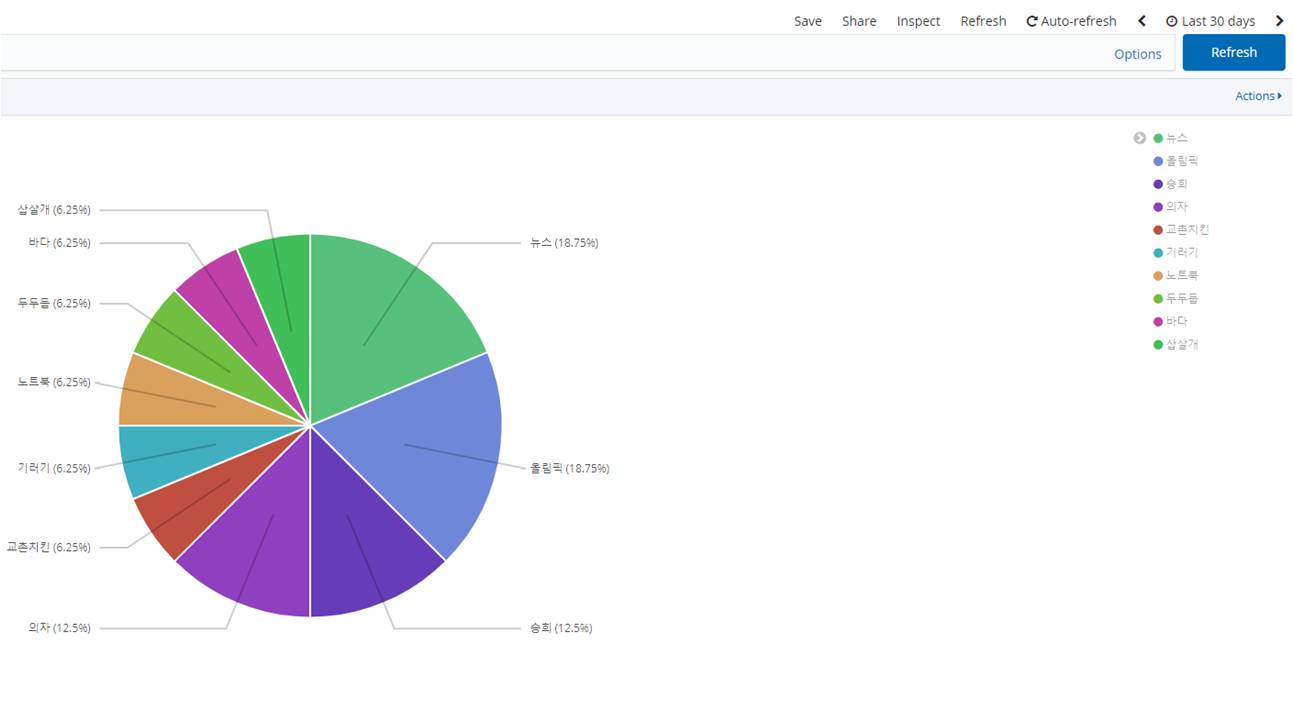 Kibana
Kibana
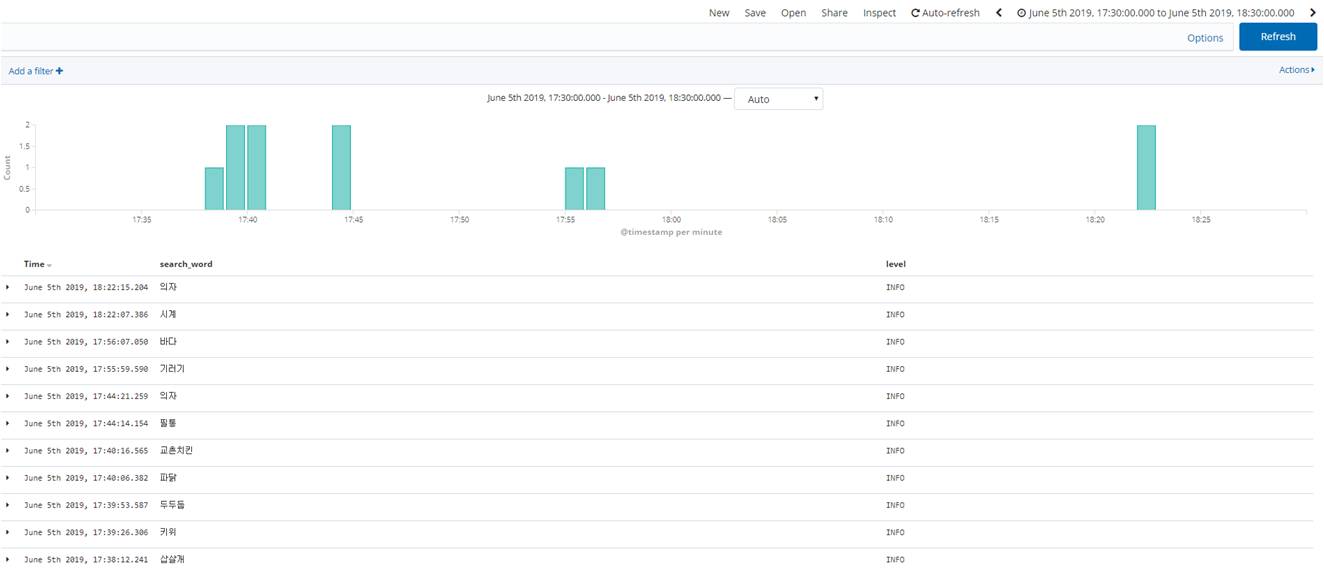 Kibana
Kibana
Kibana에서는 위와 같이 지난 30일 동안 어떤 단어가 많이 검색되었는지, 설정한 시간 동안 어떤 단어들이 검색되고 있었는지 분석이 가능합니다. 또한 WARNING level의 로그들만 추출하여 문제점을 파악할 수 있는 등 Kibana의 유용한 기능들을 활용하여 여러 가지 로그 분석이 가능합니다.
- Curator로 오래된 로그 자동관리
서비스를 장기간 운용하게 되면 과거의 많은 로그가 디스크 공간을 차지하게 됩니다. 기간 및 디스크 크기 기준으로 오래된 로그를 지워주는 프로그램인 Curator를 사용하여 잘 보지 않는 과거의 로그들을 자동으로 관리할 수 있도록 합니다.
먼저, pip를 사용해 elasticsearch-curator를 설치합니다.
pip install elasticsearch-curator
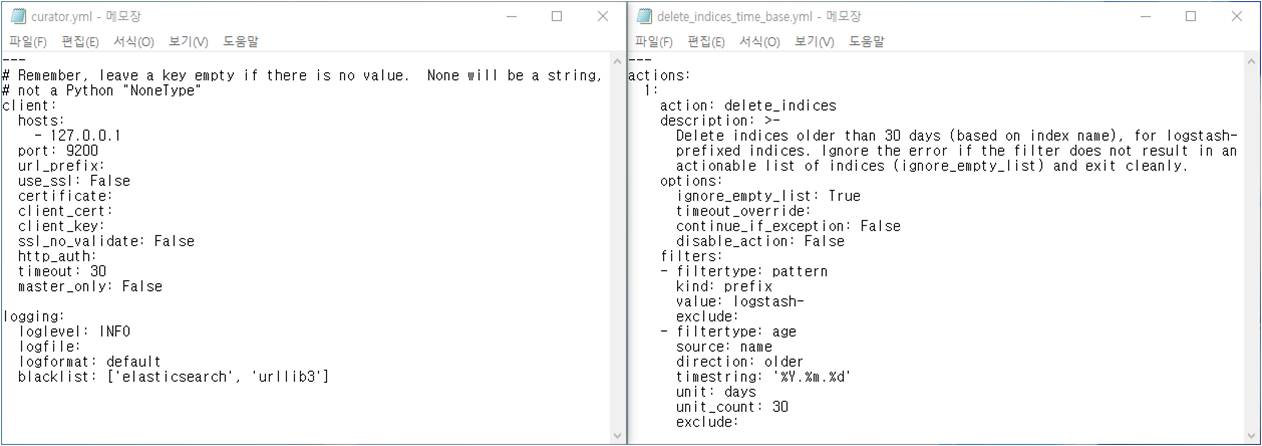 Curator 설정
Curator 설정
local의 Elasticsearch에서 ‘logstash-‘로 시작하는 인덱스가 30일이 지났으면 지우도록 두 파일을 설정하고 Curator를 실행합니다. 그러면 Curator는 Elasticsearch에 30일이 지난 로그가 있는지 확인하고 있다면 삭제합니다.
리눅스에서는 cron, 윈도우에서는 작업 스케줄러를 사용해 매일 한 번씩 Curator를 실행시키도록 설정해주면 매일 30일이 지난 인덱스가 있는지 체크하면서 오래된 로그를 지워줍니다.
- AWS S3를 활용한 로그 백업 및 복원
먼저 Elasticsearch에서 로그 데이터를 S3에 간단히 백업할 수 있도록 repository-s3 플러그인을 설치합니다.
C:\Users\user\elasticsearch-6.6.2\bin>elasticsearch-plugin install repository-s3
로그를 백업할 저장소 지정
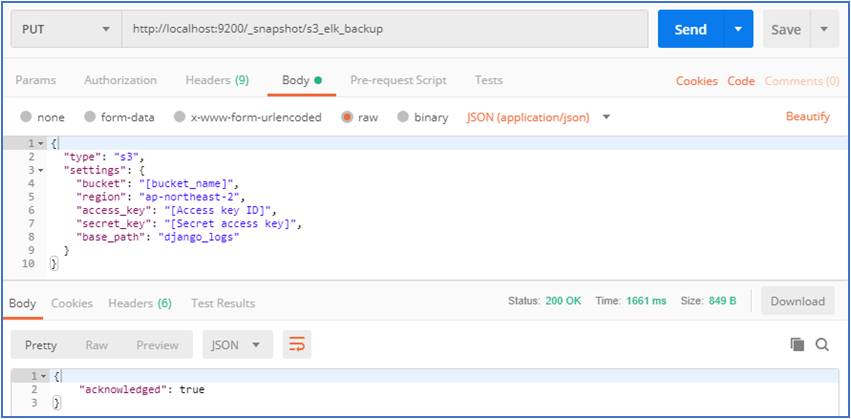 로그를 백업할 저장소 지정
로그를 백업할 저장소 지정
로그를 백업할 저장소를 지정합니다. bucket, region을 각각 입력하고 S3 접근 권한을 가진 IAM 사용자를 추가해 생성된 access key, secret key를 입력해주었습니다.
 AWS S3
AWS S3
base_path 설정대로 django_logs 폴더가 생성된 것을 확인할 수 있습니다.
S3에 로그 백업
Elasticsearch에서는 버전별로 데이터를 저장하여 이전 상태를 유지할 수 있는 snapshot이라는 기능을 제공하는데 이 snapshot 기능을 사용하여 S3에 로그를 백업합니다.
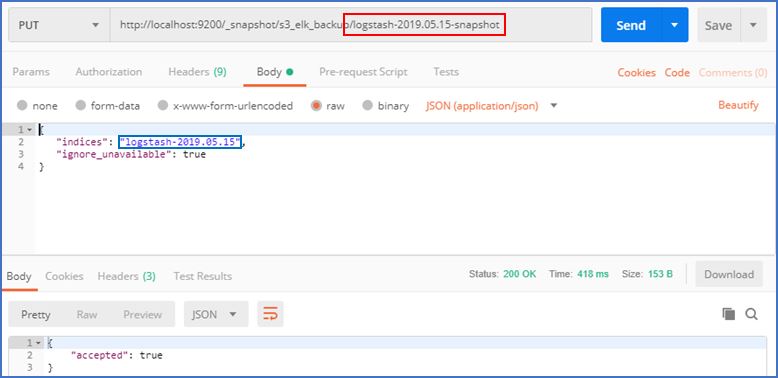 snapshot생성
snapshot생성
빨간 박스처럼 snapshot이름을 설정하고 파란 박스처럼 백업할 인덱스를 지정합니다.
S3에 저장되어있는 로그 복원
복원 테스트를 해보기 위해 2019년 5월 15일 로그를 지워보았습니다.
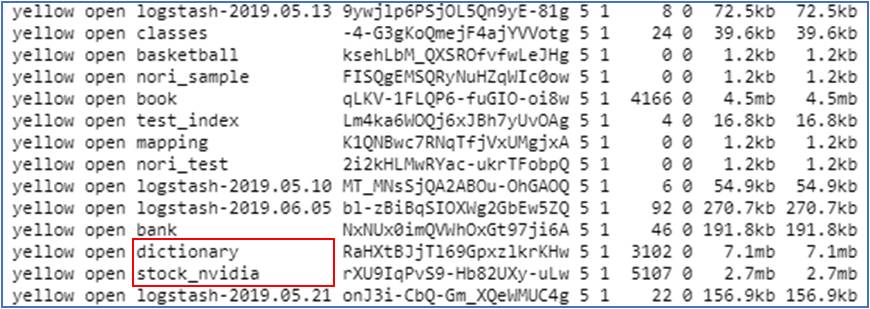 복원하기 전 인덱스들
복원하기 전 인덱스들
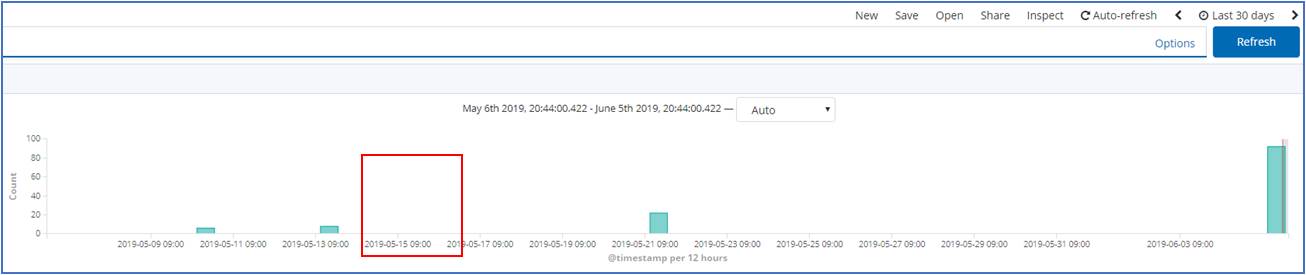 복원하기 전 (Kibana)
복원하기 전 (Kibana)
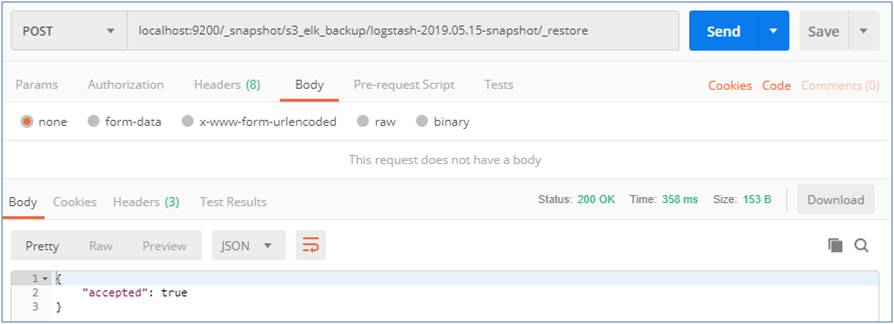 S3에 저장되어있는 로그 복원
S3에 저장되어있는 로그 복원
복원할 snapshot을 지정하고 복원해줍니다.
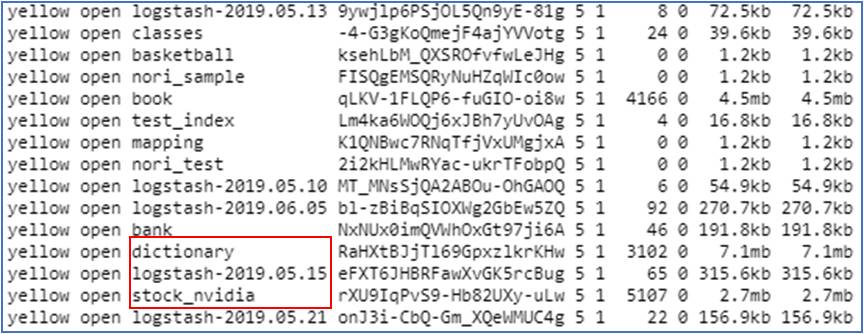 복원된 logstash-2019.05.15
복원된 logstash-2019.05.15
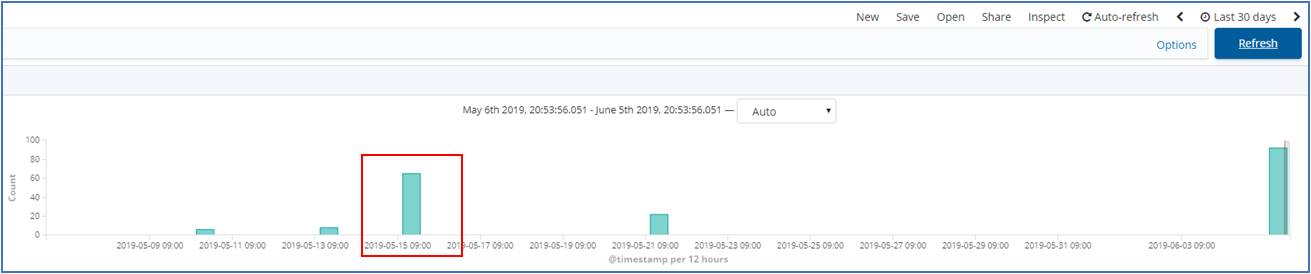 복원된 2019년 5월 15일 로그 (Kibana)
복원된 2019년 5월 15일 로그 (Kibana)
손쉽게 백업하고 복원되는 것을 확인할 수 있습니다.
이것 또한 리눅스에서는 cron, 윈도우에서는 작업 스케줄러를 사용해서 매일 자정에 어제 쌓인 로그들을 AWS S3에 백업하도록 설정해주어 Curator가 지웠더라도 언제든지 복원하여 분석할 수 있습니다.
Result
ELK Stack을 활용해서 Django에서 생성되는 로그들을 가공해서 저장하고 여러가지 분석을 해보았습니다. 또한, Curator로 디스크 공간을 낭비하는 오래된 로그를 관리하고 AWS S3로 백업 및 복원하는 방법에 대해서도 알아보았습니다. 그 외에도 Logstash에서 client IP를 통해 geo_point 데이터를 추출하고 Kibana를 통해 지도에 표시해주는 재미있는 기능도 있습니다. 다음엔 이 기능을 활용하여 지역별 분포 분석, 지역별 검색 키워드 분석도 해보려고 합니다.