
머리
흔히 YOLO(욜로)라고 하면 You only Live Once 의 약자로 ‘인생은 오직 한번뿐’ 이라는 의미로 자유로운 라이프 스타일을 나타냅니다😎
하지만 이 포스팅에서는 조금 다른 YOLO를 다룹니다. ‘You Only Look Once.’ 즉 한번에 보고 바로 처리를 하겠다. 라는 속도가 빠르다는 장점을 내세운 Object Detection 신경망 입니다. YOLO는 yolov1부터 2020년 7월 기준으로 yolov5 까지 공개되어 개발자분들 뿐만 아니라 비전공자들부터 학생들까지, 많은 사람들이 인용하여 활용 및 연구중입니다. 이번 포스팅에서는 YOLOv1부터 YOLOv2까지 모델 구조와 특징들에 대해 차근차근 설명해보려고 합니다.
가슴
YOLOv1
기존의 Object Detection은 single window나 regional proposal methods등을 통해 바운딩 박스를 잡은 후 탐지된 바운딩 박스에 대해 분류 수행하는 2 stage detection 으로, image detection을 완료하는 알고리즘을 통해 진행되었습니다. 파이프라인이 복잡하기 때문에 당연히 학습과 예측이 느려지고 최적화도 느려집니다.
YOLOv1은 하나의 컨볼루션 네트워크를 통해 대상의 위치와 클래스를 한번에 예측합니다.
(한 번만에 image detection을 할 수 있는 1 stage detection 알고리즘)
YOLO가 등장했을 당시 장점으로 주목을 받았던 내용들입니다.
- 학습 파이프라인이 기존의 detection 모델들에 비해 간단하기 때문에 학습과 예측의 속도가 빠르다.
- 모든 학습 과정이 이미지 전체를 통해 일어나기 때문에 단일 대상의 특징뿐 아니라 이미지 전체의 맥락을 학습하게 된다.
- 대상의 일반적인 특징을 학습하기 때문에 다른 영역으로의 확장에서도 뛰어난 성능을 보인다.
YOLO 모델의 구조
테두리상자 조정 (Bounding Box Coordinate)과 분류(Classification)를 동일 신경망 구조를 통해 동시에 실행하는 통합인식(Unified Detection)을 구현하는 큰 특징을 가지고 있습니다.
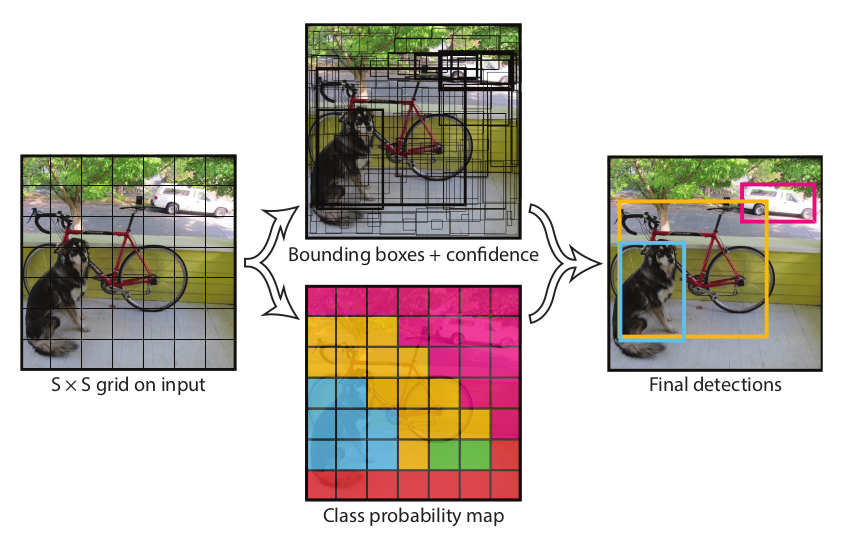
- 이미지를 SxS 의 그리드로 분할합니다. (논문에서는 S = 7로 예시를 두었습니다.)
- 이미지 전체를 신경망에 넣고 특징 추출을 통해 예측 텐서(Prediction Tensor) 생성합니다.
여기서 예측 텐서는 그리드 별 테두리상자 정보, 신뢰 점수, 분류 클래스 확률을 포함합니다.
- 그리드 별 예측 정보를 바탕으로 테두리 상자 조정 및 분류 작업 수행합니다.
- 각각의 Grid cell 은 B개의 Bounding Box와 각 Bounding box에 대한 Confidence-Score를 가집니다.
Confidence-Score : $Pr(Object) * IOU$
- 각각의 Grid cell 은 C개의 Conditional Class Probability를 가집니다.
- 각각의 Bounding box는 x, y좌표, w, h, confidence를 지닙니다.
(x, y) : Bounding box의 중심점을 의미하며 grid cell 범위에 대한 상대 값
(ex) x가 grid cell 가장 왼쪽, y가 grid cell 중간에 있다면 x=0, y=0.5
YOLOv1 Network
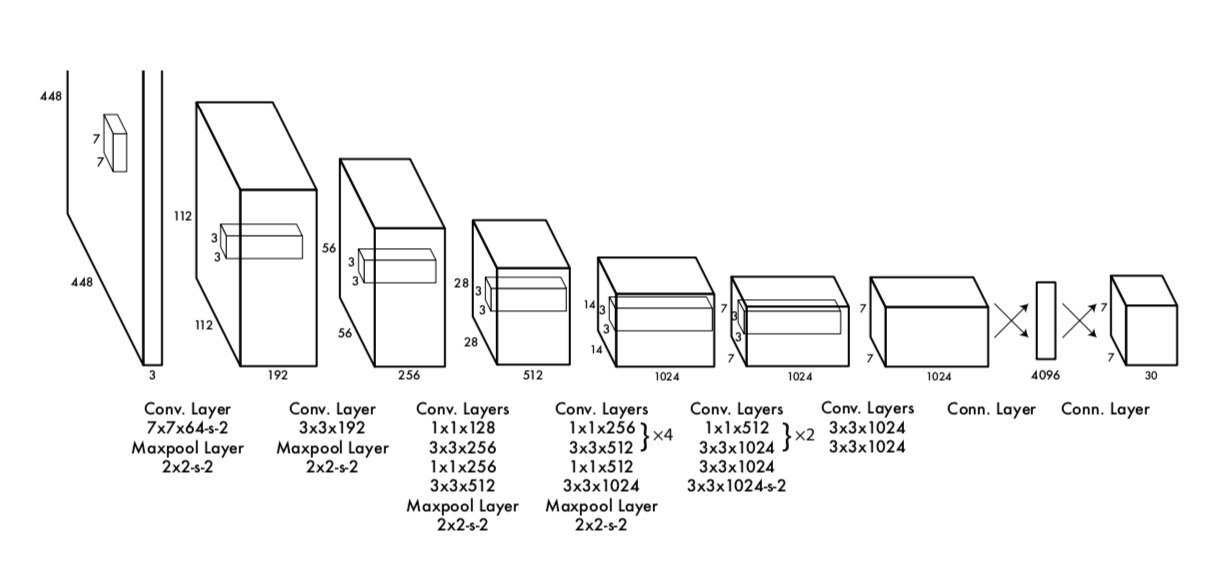
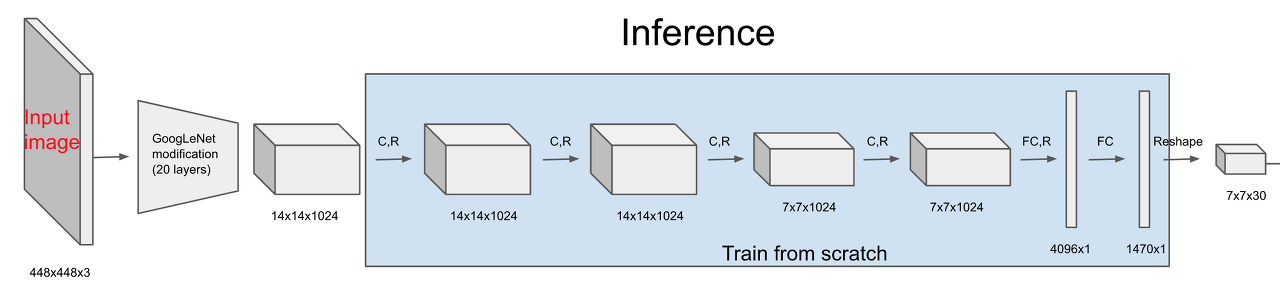
논문의 YOLO Network
Inception 블럭 대신 단순한 224x224 크기의 ImageNet Classification으로 pretrain을 진행했습니다. 이후 448x448 이미지를 input image로 받아 24개의 Conv Layer 중 앞의 20개의 컨볼루션 레이어는 고정한 채 뒷 단의 4개의 레이어와 2개의 Fully Connected Layer만 object detection task에 맞게 학습하게 됩니다. 이후 예측 텐서(Prediction Tensor)를 뽑아내게 됩니다. 이것을 바탕으로 디텍션 및 분류작업을 수행하게 됩니다.
이제 네트워크의 출력인 Conv Layer, FC Layer를 통과한 Prediction Tensor (7 x 7 x 30) 피쳐맵에 대해서 알아보겠습니다.
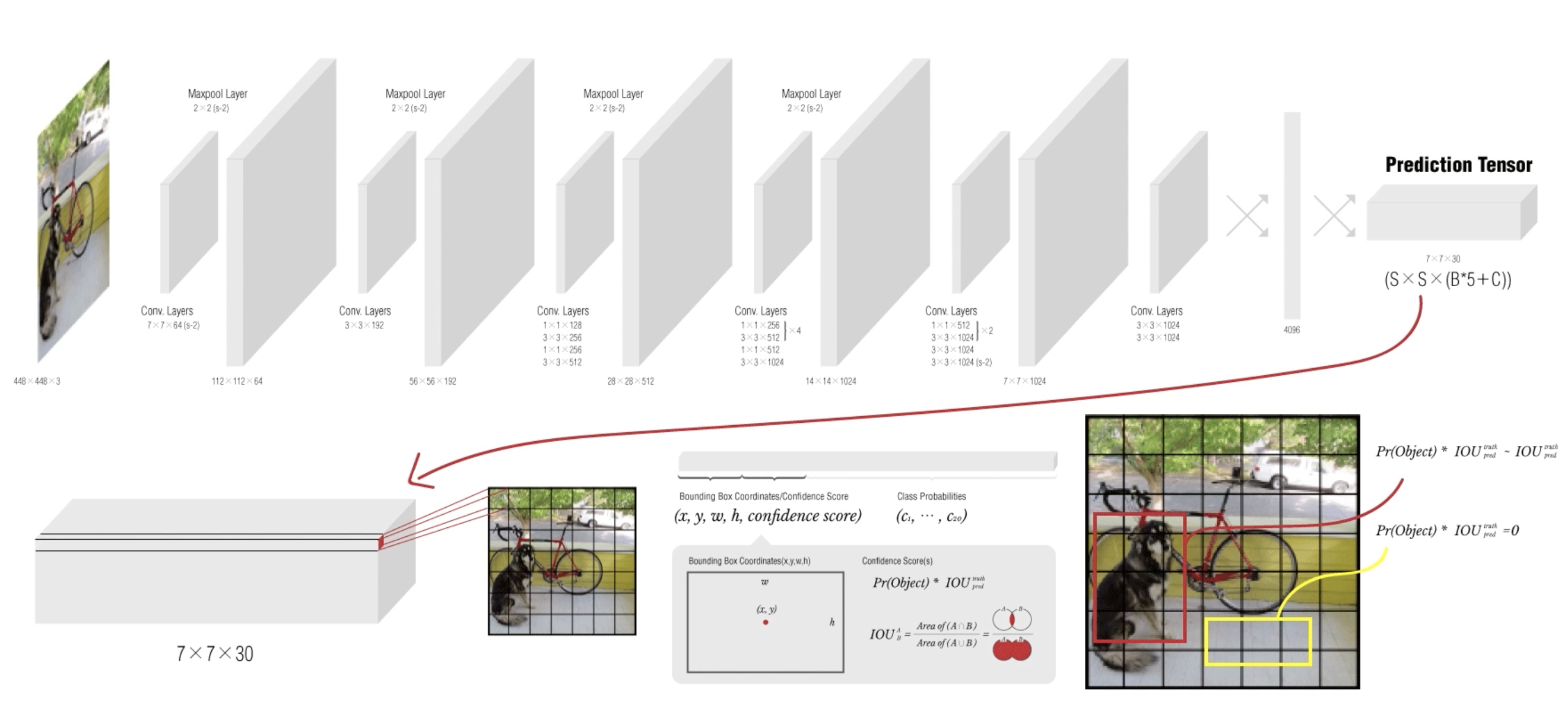
위의 그림에서는 Prediction Tensor가SxSx(Bx5+C)와 같이 되어 있습니다. 위에서 알 수 있듯이 YOLO 논문에서는 S의 크기를 7로 명시한 것을 알 수 있습니다. 7x7은 그리드의 숫자를 의미하며 7x7의 그리드 별로 30의 길이를 가지는 값을 의미하게 됩니다.
그럼(Bx5+C)는 어떻게 나왔을까요?
B는 각각의 그리드별로 갖는 Bounding Box 후보의 개수를 나타냅니다. (논문에서는 2개씩 가지겠다. 라고 설정을 했죠) 이것은 다시 말해 하나의 그리드 안에 (x, y)가 위치해있는(바운딩 박스의 중앙점이 위치해있는) 바운딩 박스들을 2개를 선정하겠다는 말이 됩니다.
5 라는 값은 x, y, w, h, confidence score 의 의미를 갖습니다.
C는 클래스의 개수를 나타내며 20개의 클래스를 갖습니다.
자, 이제 정리를 해보면 Image → CNN → FC → PT(Prediction Tensor) 과정을 거치게 되고 이 과정으로 PT를 뽑아내는데, Conv Layer, FC Layer를 통과한 PT에 대해서는 30(PT) = 5(x,y,w,h,confidence score) x 2(bounding box) + 20(ImageNet 클래스 개수)과 같이 말할 수 있으며, 이 PT 바탕으로 값을 조정하여 학습을 한다. 라고 할 수 있습니다.
Loss
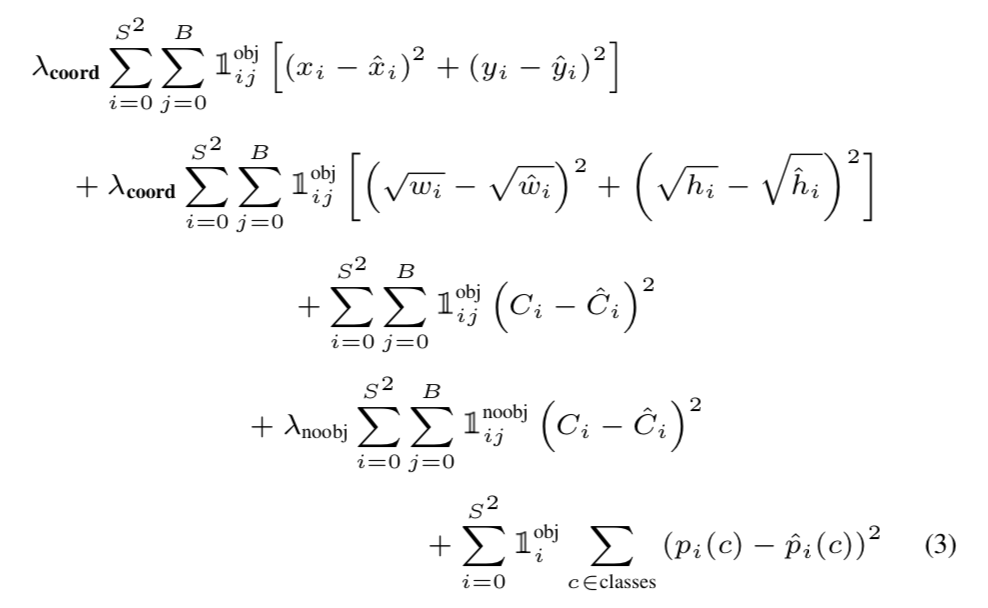
MULTI Loss
= Coordinate Loss + Confidence-Score Loss + No-Object Penalties + Classification Loss
PT = (x, y, w, h, Confidence-Score) x B + Classes 에 대해서 x, y는 수식의 1번 라인. w, h는 2번 라인. Confidence-Score는 3~4번 라인. Classes는 5번 라인에 대한 것들을 의미합니다.
그래서 MULTI Loss를 보면 Coordinate Loss(x, y, w, h)에 대한 수식이 있고(1~2번 라인) Confidence-Score Loss에 대한 수식(3번 라인), No-Object Penalties에 대한 수식(4번 라인), Classification Loss에 대한 수식(5번 라인)으로 이루어진 구조로 되어있습니다
수식만 보게 되면 굉장히 복잡해 보입니다.. 하지만 간단히 보면 x, y, w, h, Confidence-Score의 값이 예측값과 Ground-truth 값의 차를 구해 모두 더해준다는, 크게 어렵지 않은 내용입니다. 이후 패널티 단락에서 찾지 못한 물체들에 대한 패널티를 부여합니다. 다시 말해 물체로 찾아냈어야 하는데 찾지 못한 인덱스에 대해 C의 값의 차를 구해 loss에 더해줍니다. 마지막 단락에서 모든 물체가 있다고 판단된 인덱스들에 대해 모든 클래스들에 대해 예측 값과 실제 값의 차를 구해서 더해줍니다.
이번 포스팅에서는 간략히 개념에 대해서 짚고 가기 위해 여기까지만 짚고 넘어가겠습니다.🤦🏻♂️
YOLOv1의 한계
YOLOv1에서는 여러 물체들이 겹쳐있으면 제대로 된 예측이 어렵습니다. 또한 물체가 작을 수록 정확도가 감소하며 바운딩박스 형태가 data를 통해 학습되므로 새로운 형태의 바운딩박스의 경우 정확히 예측하지 못한다는 단점이 있습니다.
YOLOv2
이러한 YOLOv1 모델의 문제점을 보완하여 정확도를 높인 YOLOv2 가 등장하였습니다.
YOLOv2는 기존의 YOLO에서 성능을 올리기 위해 많은 점을 보완하였습니다. YOLOv2 에서의 핵심은 이전의 YOLO와는 다르게 Anchor Box의 개념 도입, Batch Normalization 적용, features map 크기를 7x7 에서 13x13으로 변경 하는 등의 방법을 통해 성능개선을 이뤘습니다.
개선 사항
- Batch Normalization 적용
YOLO의 Convolution Layer에 Batch Normalization을 적용하여 mAP를 2% 가량 향상시켰습니다.
- High Resolution Classifier
YOLOv1은 VGG16 모델을 기반으로 224x224 크기의 해상도로 학습을 하고, 448x448 크기의 이미지에 대해서 Object Detection을 수행하도록 설계되어 성능이 좋지 않았습니다. YOLOv2에서는 학습 전 이미지 분류 모델을 큰 해상도의 이미지에 대해 fine-tuning 단계를 거쳐 고해상도 이미지로 CNN 신경망을 학습 할 수 있었습니다. 그 결과 약 4%의 mAP 증가의 결과를 도출했습니다.
- Convolutional With Anchor Boxes
기존의 YOLOv1은 24개의Conv layer와 마지막 단락의 2개의 Fully Connected layer로부터 바운딩박스의 좌표정보를 예측했습니다. YOLOv2는 마지막 단의 Fully Connected layer을 떼어내고 Convolutional Network 형태로 prediction을 계산합니다.
또한, Anchor Box의 개념을 도입하여 바운딩 박스의 좌표를 예측하기 보다는 사전에 정의한 앵커 박스에서 offset을 예측하여 더욱 간단하게 학습을 할 수 있게 되었습니다. Anchor Box의 핵심은 사전에 크기와 비율이 모두 결정되어 있는 박스를 전제로, 학습을 통해서 이 박스의 위치나 크기를 세부 조정하는 것을 말합니다.
-
Dimension Cluster
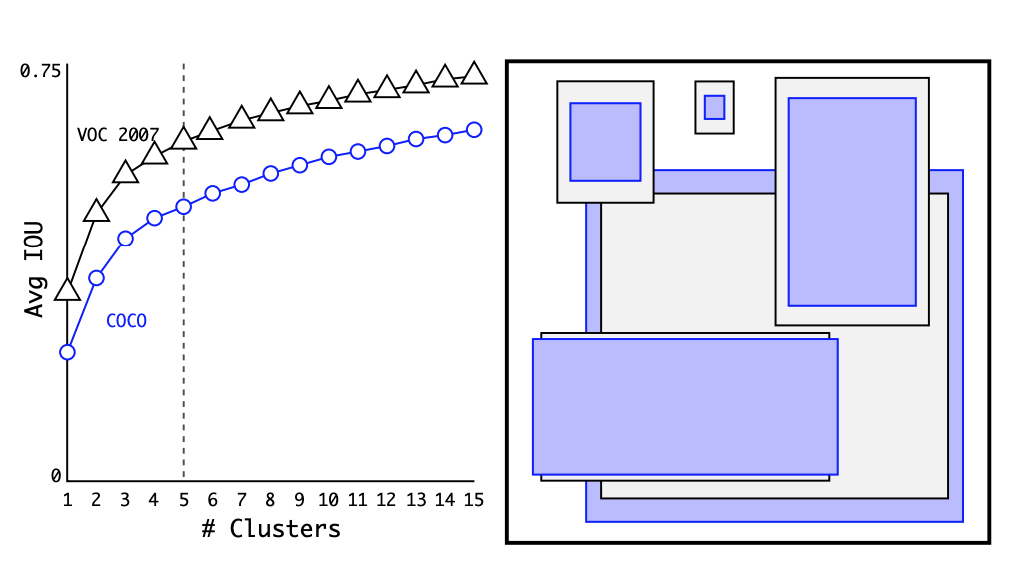
YOLOv2는 앵커박스를 수정하면서 바운딩 박스를 예측합니다. 그렇기 때문에 실제 경계 박스들을 클러스터링 하여 최적의 앵커박스를 찾습니다.
클러스터링 갯수 k 를 크게 늘릴수록 클러스터링 결과와 라벨과의 IOU가 커져 Recall이 상승합니다. 그러나 k가 커지면 높은 정확도를 얻을 수 있지만 속도가 느려지기 때문에 YOLOv2에서는 k=5라는 값을 사용합니다. (YOLOv2 에서는 앵커 박스를 5개 사용합니다.) 그 결과 recall과 precision 측면에서 성능을 향상시킬 수 있었습니다.
-
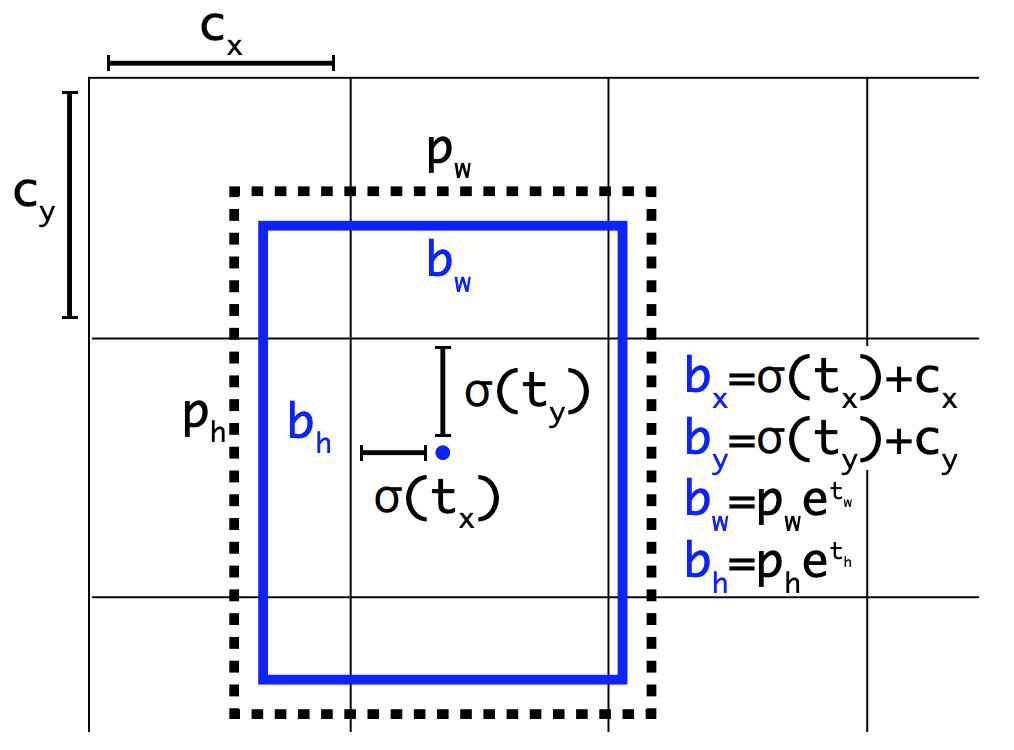
Direct location prediction
YOLOv2에서는 앵커 박스에 따라 하나의 셀에서 5차원 벡터로 이루어진 바운딩 박스를 예측하며, 경계 박스가 그리드 셀에서 벗어나지 않도록 제약을 둡니다. 기존의 YOLO가 그리드의 중심점을 예측하였다면 v2에서는 left top 꼭지점으로부터 얼마나 이동하는지 예측하게 됩니다.
-
Fine-Grained Features
위에서 YOLOv2는 13x13 feature map을 출력한다고 설명했었습니다. 하지만 13x13의 크기는 작은 물체 검출에 대해서 약하다는 단점이 있습니다. 이와 같은 문제해결을 위해 상위 레이어의 피쳐맵을 하위 피쳐맵에 합쳐주는 passthrough layer를 도입했습니다. 이전 layer의 26x26 feature map을 가지고 와서 13x13 feature map에 이어 붙입니다. 크기가 달라 그냥 이어붙일 수 없으므로 26x26x512의 feature map을 13x13x(512*4)의 feature map으로 변환합니다. 26x26 크기의 feature map에 고해상도 특징이 담겨 있기때문에 이를 활용 하는 것입니다.
- Multi-Scale Training
YOLOv2는 작은 물체도 detection 하기 위해 여러 스케일의 이미지를 학습하도록 하였습니다. 10 epoch 마다 {320, 352, …, 608} 과 같이 32 픽셀 간격으로 입력 이미지의 해상도를 바꿔주며 학습을 진행합니다. 따라서 다양한 입력 크기에도 예측을 잘할 수 있습니다.
YOLOv2 Network
위에서 설명한 것들을 다시 한번 참고하여 YOLOv2의 네트워크에 대해서 한번 더 짚고 갑시다.
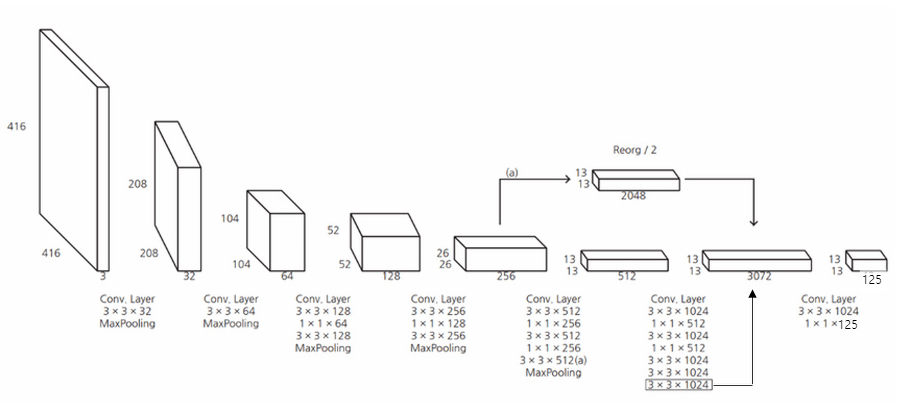
먼저 YOLOv2 가 더 빨라진 이유는 기존의 YOLO는 VGG-16 신경망을 사용했다면 YOLOv2는 Darknet 19 신경망을 구축하여 이용했습니다. VGG-16 신경망에서 대부분의 가중치가 쓰인 FC layer를 제거하여 가중치 파라미터 수를 낮춰줬기 때문에 훨씬 빠른 속도로 detection이 가능하게 되었습니다.
YOLOv2 Network
위에서 이미 한 번 보고온 네트워크 구조입니다. 기존의 YOLO 구조에서 변경된 점은 위의 Fine-Grained Features 에서 설명한 것과 같은 내용과 같습니다. YOLOv1과 YOLOv2의 output 을 비교해보면 v1의 최종 output은 7x7x30 이며 채널 30의 값은 (5xB+C)로 즉, (5x(바운딩박스 수)+(클래스 개수)) 이기 때문이라고 설명했었습니다. 그럼 YOLOv2 의 최종 output은 위에서 13x13x125 임을 확인할 수 있습니다. 125라는 값이 어떻게 나올까요? 보기 쉽게 정리된 그림입니다.
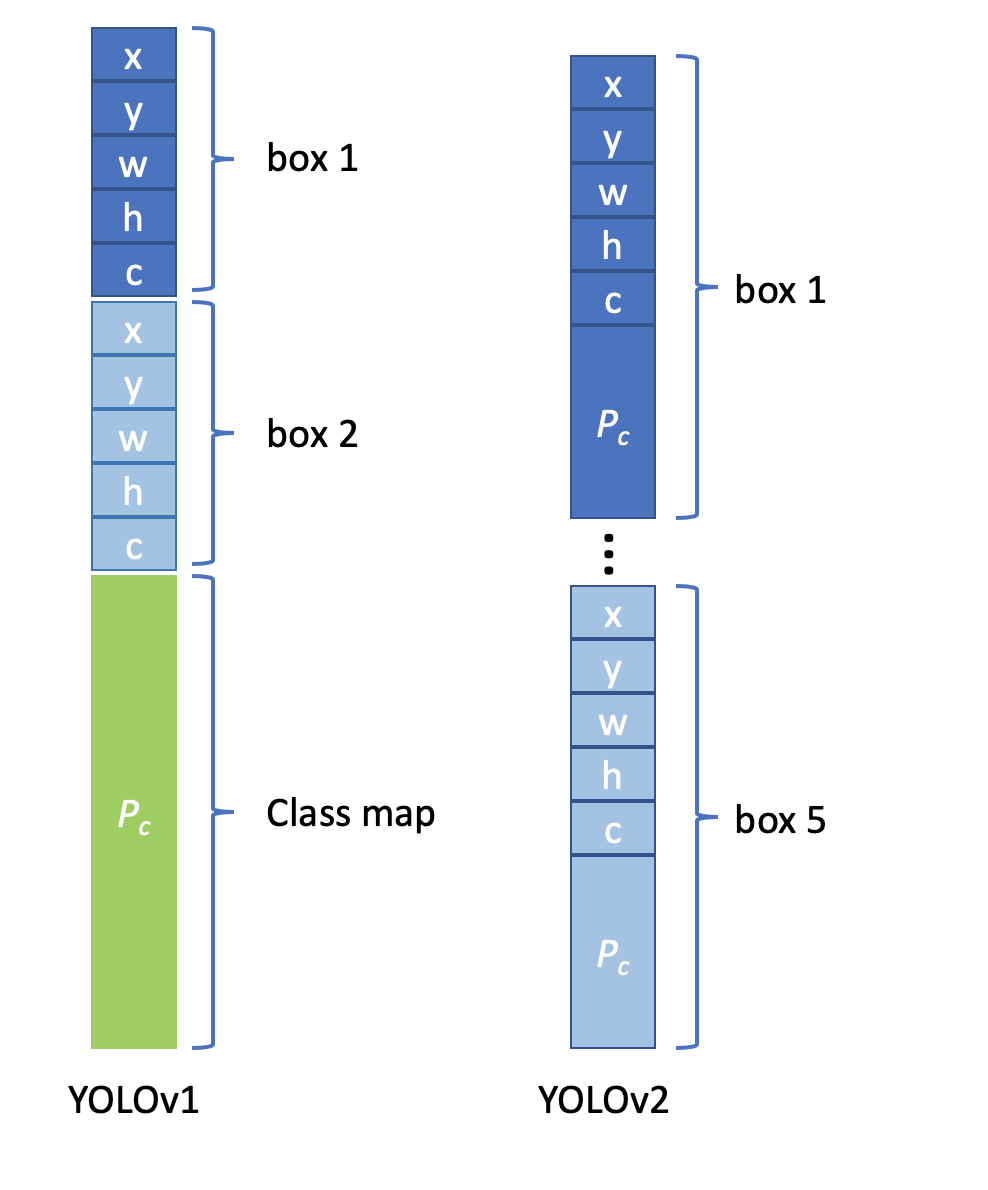
YOLOv2에서 앵커박스를 적용했을 때 각각의 앵커박스에 대해서 classification 정보를 가지고 있습니다. 다시 말해 하나의 anchor box에 대해 prediction을 하는데 각 prediction은 x, y, w, h, confidence, class갯수(20) 이렇게 총 25개를 의미합니다. 따라서 YOLOv2는 총 5개의 anchor box를 가지고 있기때문에13x13x(Bx(5+C)) 로 13x13x125 라는 output이 최종적으로 나오는 것을 확인 할 수 있습니다.
YOLOv2 성능 및 결과
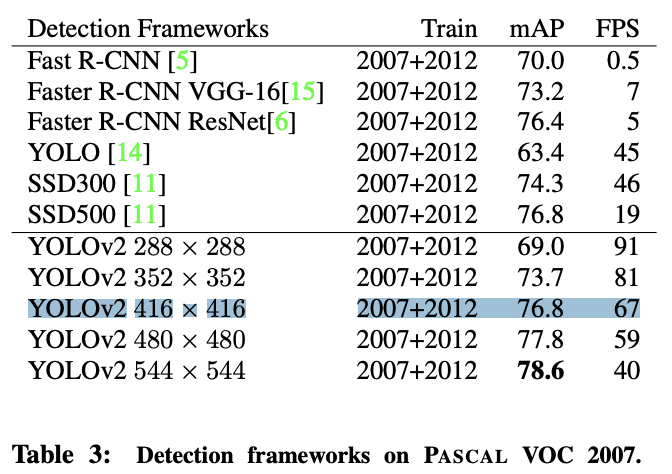
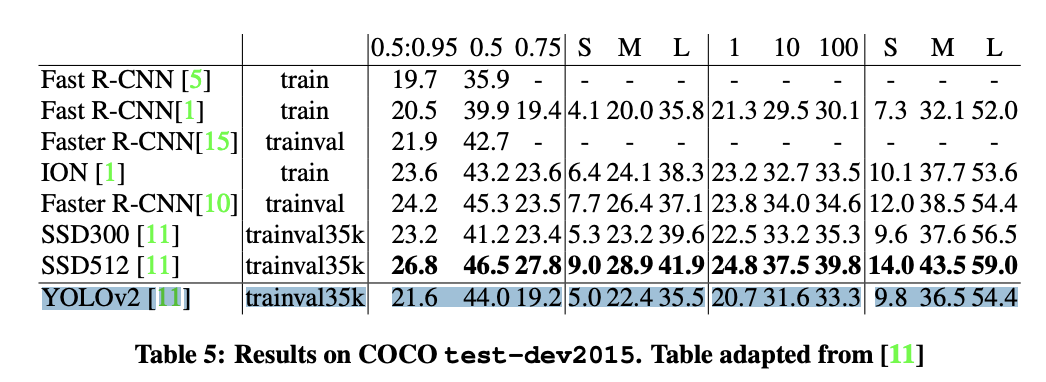
YOLOv2는 상당히 빠르면서도 높은 성능을 보여줍니다. voc 207 과 coco 결과를 보면 voc에서는 SSD 알고리즘 보다 높은 성능을 보이지만, coco에서는 좀더 낮은 성능을 보여줍니다.
배
복잡하지 않은 pipeline과 빠른 예측속도를 유지하면서도 정확도에 대해 높은 성능을 예측한다는 장점이 더 부각되기 때문에 YOLO가 Object Detection 분야에서 한 획을 그었으며 관심을 받고 있는 것이라 생각이 듭니다.
다음 포스팅에서는 보다 더 발전한 YOLOv3 부터 YOLOv5 까지의 구조를 가지고 다시 찾아오겠습니다!
참고자료
You Only Look Once: Unified, Real-Time Object Detection
YOLO9000: Better, Faster, Stronger
PR-023: YOLO9000: Better, Faster, Stronger
십분딥러닝_14_YOLO(You Only Look Once)