여는 글
오늘은 주로 자연어 처리 분야에서 사용하는 기법을 개인화 추천 분야에 어떻게 적용하는지에 대해 알아보겠습니다!
 출처 - 카카오 기술블로그
출처 - 카카오 기술블로그
1. 개인화 추천 기술란?
먼저 예시를 들어보겠습니다.
아래는 인터넷 쇼핑몰에서 Best 추천 상품을 받아보는 화면입니다.
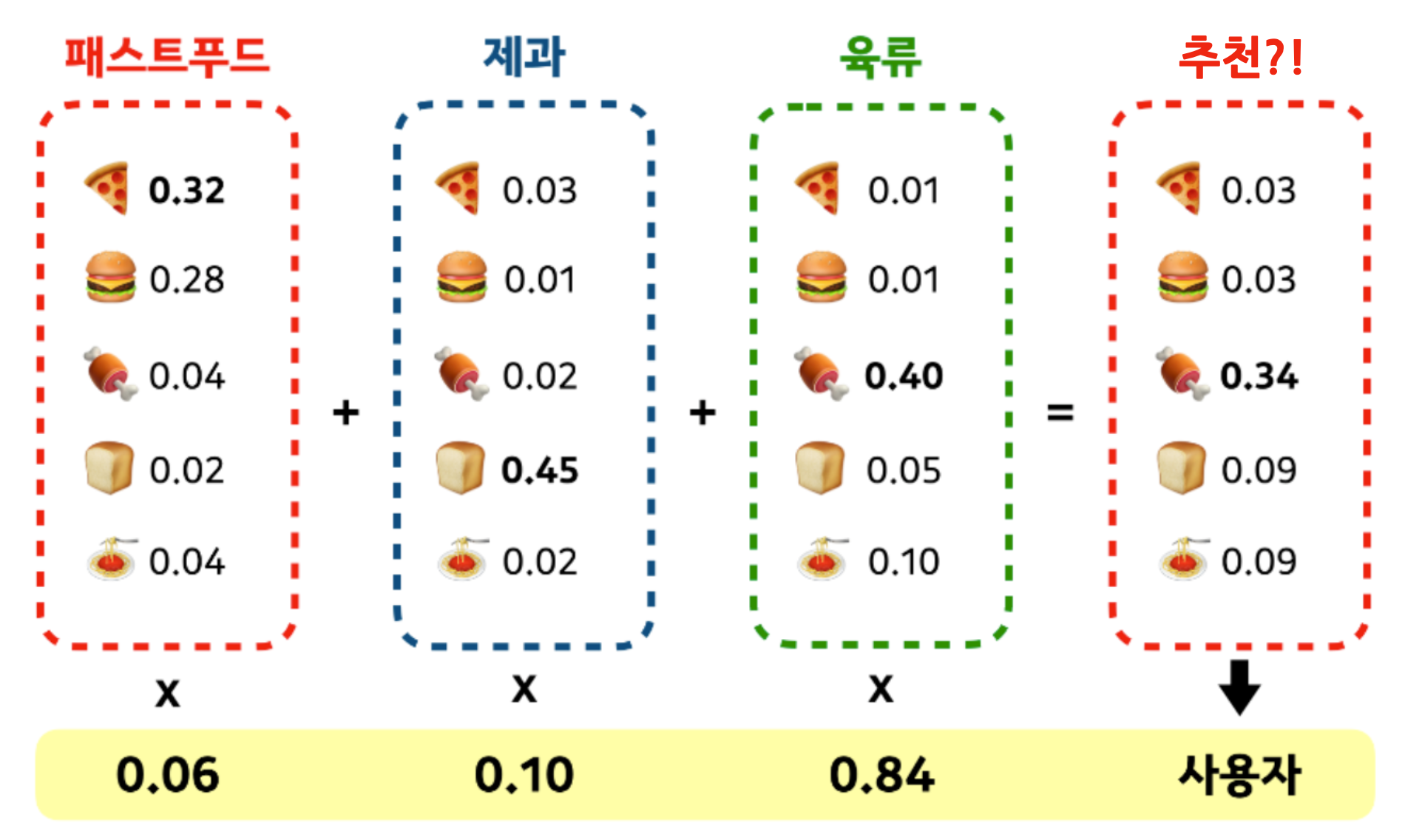
가장 앞단에 추천되고 있는 김치에 대해 평균적으로 기대할 수 있는 구매율을 N%라고 계산했을 때, 이는 모든 사람에게 동일하게 기대할 수 있는 값은 아닙니다.
 출처 - 아자몰
출처 - 아자몰
예를들어, 사용자1은 평소에 김치 소비를 많이하는 편이고, 매번 김치를 사먹기때문에 이 상품을 보자마자 클릭 할 가능성이 높은 편입니다.
반면 사용자2는 김치 소비가 적은 편이고, 집에서 직접 김장을 하기때문에 이 상품을 보더라도 구매(심지어는 클릭조차)하지 않을 수도 있습니다.
이처럼 각 개인별 각 상품에 대한 기대 구매율을 계산하고 기대 구매율이 가장 높은 상품들을 맞춤형으로 제시해 주는 것이 개인화 추천 기술이라고 합니다.
다양한 개인화 추천 방법론이 있지만 그 중에서 자연어처리에서 주로 사용되던 기법인 토픽 모델링을 개인화 추천 시스템에서 어떻게 적용하는지 알아보겠습니다.
2. 토픽 모델링이란?
배경
기계 학습 및 자연언어 처리 분야에서 주로 사용하던 비지도학습 알고리즘
위키 정의
문서 집합의 추상적인 “주제”를 발견하기 위한 통계적 모델 중 하나로, 텍스트 본문의 숨겨진 의미구조를 발견하기 위해 사용되는 텍스트 마이닝 기법 중 하나이다.
(출처 - 위키 백과 토픽모델링)
컨셉
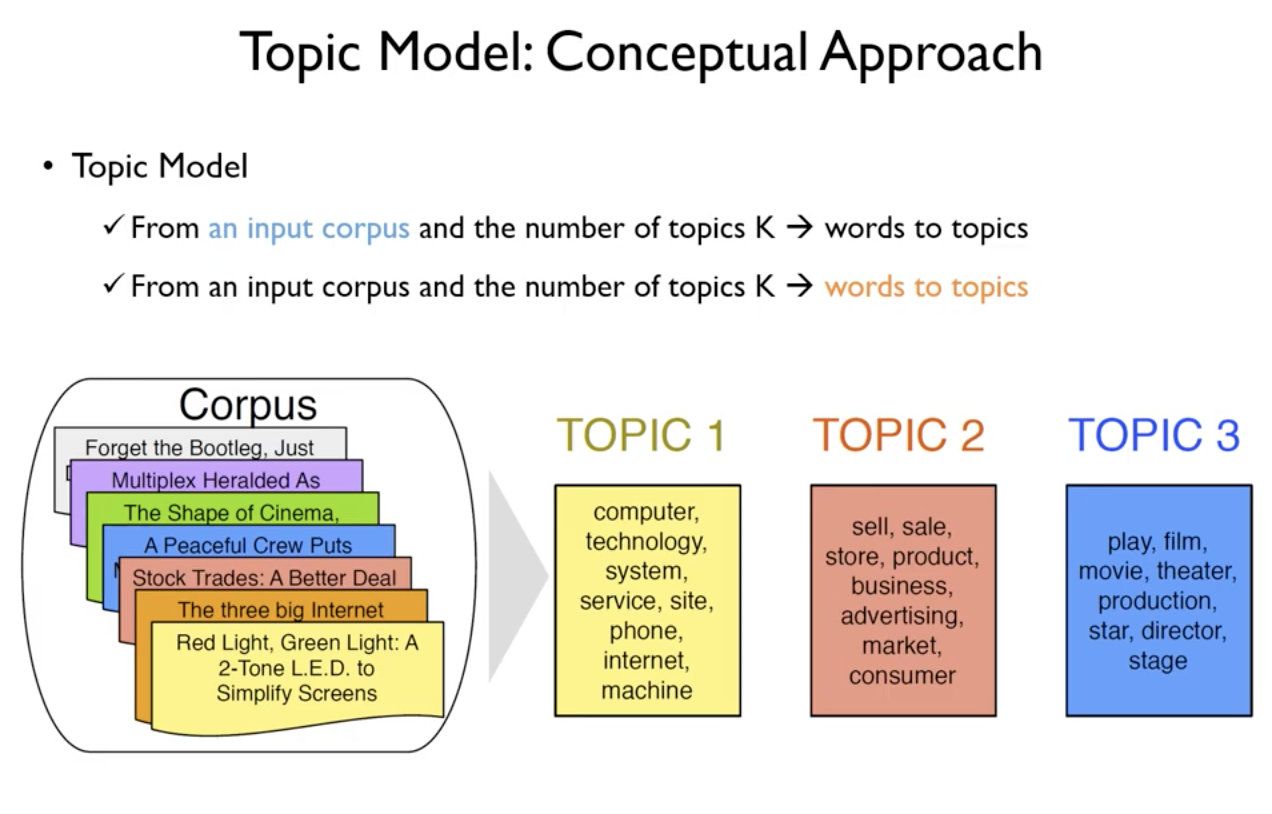
- 단어 관점
 출처 - 강필성 교수님 강의 영상
출처 - 강필성 교수님 강의 영상
- 특정한 문서의 집합(Corpus)으로부터 사전에 정의된 K개의 주제(Topic)를 만들어냄
- 각 Topic에 대응하는 높은 빈도의 Corpus의 단어들을 할당함
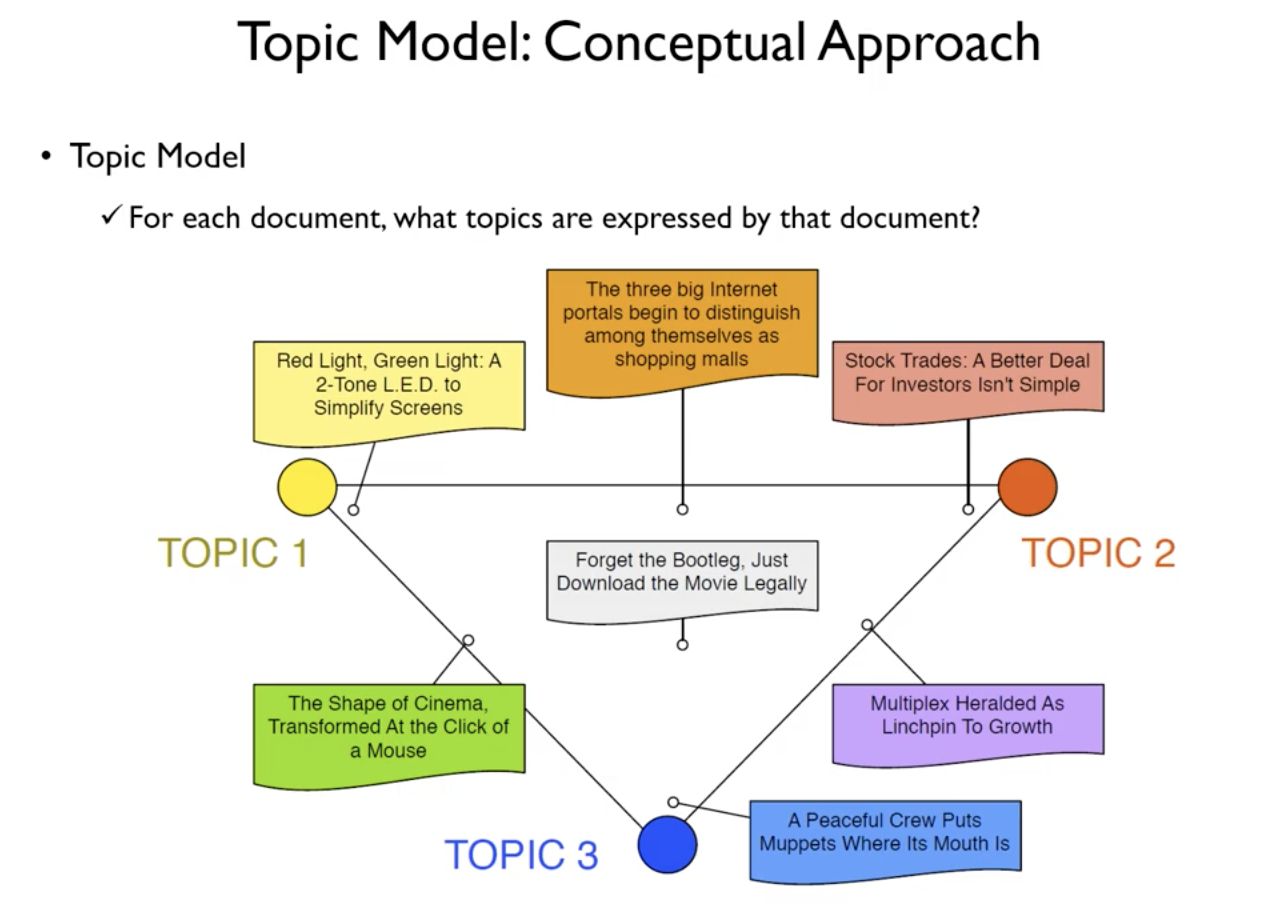
- 문서 관점
 출처 - 강필성 교수님 강의 영상
출처 - 강필성 교수님 강의 영상
- 각 개별적인 문서가 어느 토픽을 많이 포함하고 있는가?
- 각 문서에서 특정 토픽이 차지하는 비중 산출
정리
- 개별 토픽 관점
- 어떤 단어들이 주로 빈번하게 등장하는가?
- 주요 어휘들이 무엇인가?
- 개별 문서 관점
- 각각의 문서에는 각 토픽들이 얼마만큼의 비중을 가지고 섞여있는가?
토픽 모델링은 비교적으로 오래된 기법 중 하나지만, 정답이 있는 데이터가 없어도 문서들 내에 속한 단어들만으로도 학습할 수 있기 때문에 지금까지도 많이 사용되고 있는 알고리즘입니다.
(* 고려대학교 강필성 교수님 강의 영상을 참고하시면, 토픽모델링 알고리즘에 대해 더 자세하게 이해할 수 있으니 한번쯤 보시는 것을 추천드립니다!)
3. 개인화 추천에서의 토픽 모델링
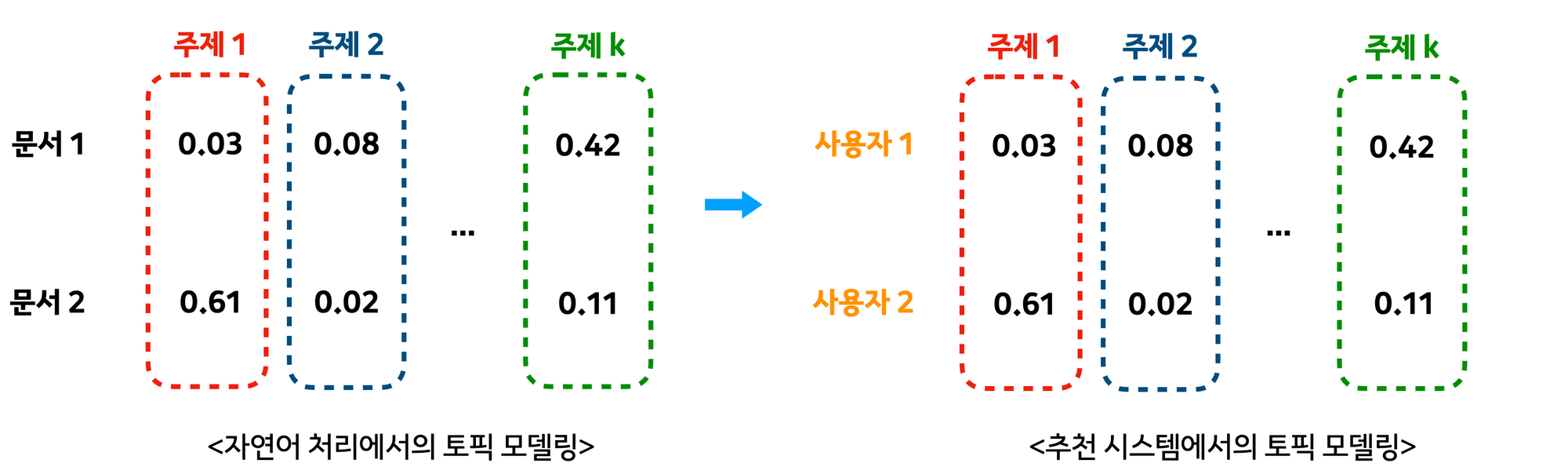
위 방식과 동일하게 토픽 모델링으로 사용자들과 콘텐츠들의 특징을 추출하게 됩니다.
단어들을 바탕으로 한 문서 안의 여러 개의 주제를 찾을 수 있는 것처럼, 상품들을 바탕으로 한 명의 사용자 안에 내포되어 있는 여러 개의 주제를 찾을 수 있다고 볼 수 있기 때문에, 토픽 모델링 기법을 개인화 추천에 적용할 수 있는 것입니다.
 출처 - 카카오 기술블로그
출처 - 카카오 기술블로그
용어만 달리하면, 단순히 “문서”, “단어”를 “사용자”, “상품 이용데이터”으로 바꿔서 보면, 아래와 같아집니다.
자연어 처리: 문서들 내의 단어들로 토픽 모델링을 수행한다.
추천 시스템: 사용자들 내의 상품 이용데이터들로 토픽 모델링을 수행한다.
결론적으로 사용자의 행동 데이터를 가지고 토픽 모델링을 수행할 수 있게 됩니다.
그 결과, 위 그림처럼 각 사용자에 대한 주제 벡터를 구할 수 있습니다.
이때, 벡터의 크기 k는 주제(토픽)의 개수이며 각각의 값은 주제에 속할 확률을 의미하게 됩니다.
추천시스템 관점에서 다시 정리하자면, 토픽 모델링을 수행하여 각 사용자별 이용한 상품데이터들이 각 주제(토픽)에 얼만큼의 비율로 속하는지를 판단하고, 이를 통해 개인화 추천을 수행합니다.
4. 예고편
추천 시스템에서 주요한 개념은 사용자가 관심있어 할 상품을 어떻게 정의하냐입니다.
영화 평점과 같이 이미 정답이 정해져있는 데이터가 아닌, 실제 사용자들의 행동 데이터를 분석하여 사용자가 관심있는 상품에 대한 정의를 내려야합니다.
전통적으로 사용하던 협업필터링과 같은 기법들은 사전에 정의된 사용자별 관심 상품들의 정답 데이터가 필요하고, 행동 데이터에서 이를 정의하는 과정에서 다양한 모순이 발생하는 경우가 생깁니다.
예를들어, 최근 한 달간 사용자1이 상품 a를 구매한 이력이 있을 경우, 사용자1은 상품 a에 관심이 있다고 판단하고 있습니다. 그런데 막상 사용해보니 사용자1은 상품 a가 마음에 들지 않았고, 환불과 같은 부정적인 피드백을 돌려주지 않았습니다. 이 상황에서 추천 시스템은 부정적인 피드백이 없었으니 사용자1과 비슷한 구매 패턴을 가진 사용자2에게 상품a를 추천해줍니다.
또 다른 예로, 2번이상 연달아 구매가 발생한 상품b에 관심이 있다고 판단을 할 경우, 매번 인기 있는 상품 몇 가지에 대해서만 추천이 일어나게되어 사용자들은 다양한 추천을 받을 수 없게 됩니다. 또 새로 추가된 신상품들은 추천 받지 못합니다.
위와 같은 모든 시나리오들을 고려하다보면, 로직이 복잡해지고 오히려 불필요한 고민들을 하게됩니다.
다음 포스팅에서는 위와 같은 고민을 덜 수 있도록, 강화학습을 추천 시스템에 이용하는 방법을 소개하겠습니다!
Reference
Probabilistic latent semantic analysis - 위키백과
토픽 모델링 - 위키 백과
고려대학교 강필성 교수님 토픽 모델링 강의 영상 - youtube
카카오 기술블로그