
이 글은 너드팩토리에서 arxiv에 등록된 연구 논문을 한글로 번역/기고한 글입니다.
Introduction
스마트폰과 같은 IT 기술이 빠르게 발전하면서 사람들이 정보에 쉽게 접근할 수 있을 뿐만 아니라 생산하기도 하면서 많은 정보들이 축적되고 있습니다. 많은 전문가들은 이를 빅데이터라고 일컫었으며 사람들이 필요한 정보를 더 신속하게 얻을 수 있을 것이라고 기대 했습니다. 하지만 역설적으로 정보가 많이 축적되면서 필요한 정보에 접근하는 시간이 더 오래 걸리는 현상이 일어나고 있습니다.
위와 같은 문제가 발생하면서 연구자들은 사용자들에게 개인화된, 특성화된 정보를 제공하기 위한 추천 시스템에 대한 연구를 진행했습니다. 여기서 추천 시스템이란 사용자의 정보를 반영하여 개인이 관심을 가질 수 있는데 도움을 주는 것입니다. 최근들어, 딥러닝과 같은 기계학습이 추천 시스템을 구성하는데에 중요한 역할을 하고 있습니다. 또한 많은 서비스에서 Goldbert에 의해 제안된 협업필터링(Collaborative Filtering 이하 CF)이라는 알고리즘을 추천 시스템에 사용하고 있습니다. 하지만 CF에는 문제점이 있습니다. 사용자의 정보가 충분하지 않는 단계인 cold start stage에서는 추천 성능을 충분히 보장할 수 없습니다. 또한 CF는 많은 수학적 계산을 토대로 이루어지기 때문에 필요한 연산량이 많다고 할 수 있습니다. 위의 문제점을 보완하기 위해서 많은 data featuring에 대한 연구를 하고 있지만 이는 알고리즘 그 자체의 문제점을 보완한다고 할 수 없습니다.
이 글에서는 다른 추천 알고리즘인 Contents Navigator(이하 CN)이라는 알고리즘을 제안하며 이 성능을 같은 데이터를 사용하여 CF와 비교합니다.
Contents Navigator & Complex System Network
먼저 CF와의 성능 비교를 하기 전 CN에 대해서 설명하려고 합니다. CF의 문제점을 보완하기 위해 우리는 사람과 정보, 정보와 사람이 어떻게 연결되어 있는지에 대해 생각했으며 이를 복잡계 네트워크에서 찾았습니다. 복잡계 네트워크의 특성 중 우리가 관심이 있었던 것은 사람과 사물이 특정한 관계를 가지고 있고 모든 것이 연결되어 있다는 것입니다. 또한 인터넷에는 데이터 전송 속도, 무선 네트워크의 승객 수, 소셜 네트워크의 인식 수준 및 대사의 응답 속도와 같은 가중치를 고려해야하는 많은 네트워크가 있습니다. 이 가중치 네트워크는 우리가 네트워크 특성을 정량적으로 이해하는 데 도움이 됩니다. 1998년, Watts와 Strogatz의 ‘Small-world network’와 Jeong과 Barabasi의 ‘scale-free network’을 시작으로 복잡계 네트워크에 대한 논문이 쏟아지기 시작했습니다. 현재는 사회학, 경제학, 물리학, 컴퓨터공학, 생물학 등 많은 분야에서 복잡계 네트워크를 활용해 연구 결과들이 도출되고 있습니다.
이를 통해 너드팩토리에서는 복잡계 네트워크를 이용해서 많은 사람들의 경험을 알고리즘화 할 수 있을 것이라고 생각했으며 이를 통해 추천 알고리즘을 설계할 수 있을 것이라고 생각했습니다. 설계한 알고리즘을 아래의 가설을 바탕으로 자연 언어로 구성되어 있으며 제목과 내용을 가지는 콘텐츠 형태의 데이터를 사용하여 성능 검증을 하고자 했습니다.
- 사용자의 추천은 해당 사용자의 경험으로부터 시작된다.
- 추천 알고리즘은 비슷한 경험을 가지는 다른 사용자로 부터 유도될 수 있다.
- 추천된 컨텐츠는 해당 사용자의 피드백을 바탕으로 수정될 수 있다.
하지만 복잡계 네트워크를 통해 추천 알고리즘을 설계하기 위해서는 특정 사용자의 경험을 인용할 한 명의 사용자가 필요합니다. 경험을 제공하는 한 명의 사용자를 복잡계 네트워크에서는 허브라고 일컫으며 허브를 찾는 일이야 말로 복잡계 네트워크를 통한 추천 알고리즘을 설계하는데 가장 중요한 점이라고 할 수 있습니다. 일반적으로 복잡계 네트워크에서는 많은 콘텐츠를 소비하는 사람이 허브가 됩니다. 하지만 단순히 콘텐츠를 많이 소비하는 사용자보다는 더 의미있는 내용을 지니는 콘텐츠를 많이 소비하는 사람을 허브라고 재정의하였습니다. 이 허브를 통해 추천을 받을 사용자가 소비할만한 다음 콘텐츠를 예측하고 추천하도록 설계하였습니다. 이 과정을 다섯가지로 축약하면 다음과 같으며 이 과정을 통해 콘텐츠를 추천합니다.
- 형태학적 분석
- 제목 혹은 내용을 이용한 글의 주제 모델링
- 유저와 선호 혹은 소모하는 글과의 매칭
- 시간에 따른 유저의 콘텐츠 소비 성향 분석
- 허브 유저의 추출 및 적절한 콘텐츠 추천
먼저 CF와 CN은 비교하기 위해서 LastFM에서 제공하는 데이터셋을 사용하였습니다. 이는 다른 논문들에서 이미 CF를 검증하는데에 쓰였던 것을 사용함으로써 더 공정한 평가를 진행하기 위함입니다. LastFM 중에서도 HetRec2011 데이터셋을 사용하였습니다. HetRec2011은 1,892명의 사용자가 92,800명의 아티스트의 음악을 청취한 것을 기록한 데이터셋입니다. 이 데이터셋은 곡명을 데이터셋화 한 것이 아니라 해당 가수의 이름을 기록하였습니다. 물론 제공하는 모든 정보를 사용하는 것이 더 좋지만 CN의 기능을 고려할 때 사용자의 시간적인 순서를 알아야하므로 데이터셋을 CN에 알맞게 전처리하여 사용하였습니다.
하지만 CF를 학습하고 평가할 때는 음악의 청취 순서 혹은 시간은 중요하지 않기에 HetRec2011에서 제공하는 데이터를 그대로 사용하였습니다.
또한 아래와 같은 식을 이용하여 각각의 알고리즘을 평가하였습니다.
\[\Sigma_{k=1}^{l} \Sigma_{i=1}^m P_m(x_k|u_i) \times \dfrac{N(x_k|u_i)}{\Sigma_{c=1}N(x_c|u_i)}\]
위의 식에서 $l$은 모든 콘텐츠의 수, $m$은 모든 유저의 수, $P_m(x_k|u_i)$는 $u_i$의 유저에게 $x_k$의 가수를 추천할 확률, $N(x_c|u_i)$는 $u_i$의 유저가 실제로 $x_c$의 가수를 청취한 횟수입니다. 위의 식을 서술하면 알고리즘이 사용자($u_i$)에게 가수를 추천할 확률에 따라서 실제로 사용자가 청취를 했는지를 평가합니다.
또한 추천 알고리즘의 경우 온라인 시스템에서 주로 사용되며 사용자가 추천을 받는데 까지 걸리는 시간도 고려해야되기에 연산이 끝난 후 사용자에게 보여주기까지 걸리는 시간도 측정하였습니다.
Collaborative Filtering
CF는 알고리즘 특성상 사용자의 콘텐츠 및 사물 소비 순서 패턴을 인식하지는 못합니다. 하지만 사용자가 성능을 평가하는 데 소비하는 콘텐츠나 사물의 소비 순서가 영향을 줍니다. 이 영향을 반영하기 위하여 이미 사용했었던 콘텐츠나 사물을 추천하였을 경우에 평가지표에서 제외되도록 하였습니다. 또한 이 상황을 반영하는 데이터셋을 새로 아래와 같이 구축하였습니다.
| User |
Artist Name |
Date |
| A |
Poets of the Fall |
2019-09-10 |
| A |
Poets of the Fall |
2019-09-11 |
| A |
Paradise Lost |
2019-09-12 |
| B |
Muse |
2019-09-11 |
| B |
Paradise Lost |
2019-09-11 |
| B |
Poets of the Fall |
2019-09-12 |
| C |
Paradise Lost |
2019-09-11 |
| C |
Poets of the Fall |
2019-09-11 |
| C |
Paradise Lost |
2019-09-12 |
| User |
Poets of the Fall |
Paradise Lost |
Muse |
| A |
1 |
0 |
0 |
| A |
1 |
0 |
0 |
| A |
1 |
0 |
1 |
| B |
0 |
0 |
1 |
| B |
0 |
1 |
1 |
| B |
1 |
1 |
1 |
| C |
0 |
1 |
0 |
| C |
1 |
1 |
0 |
| C |
1 |
1 |
0 |
Contents Navigator
CF와 달리 CN은 해당 사용자가 콘텐츠를 소비한 순서가 중요합니다. 그렇기 때문에 CF와는 다르게 시계열 정보를 포함하도록 데이터를 전처리하였습니다.
| User |
Artist Name |
Date |
| A |
Poets of the Fall |
2019-09-10 |
| A |
Poets of the Fall |
2019-09-11 |
| A |
Paradise Lost |
2019-09-12 |
| B |
Muse |
2019-09-11 |
| B |
Paradise Lost |
2019-09-11 |
| B |
Poets of the Fall |
2019-09-12 |
| C |
Paradise Lost |
2019-09-11 |
| C |
Poets of the Fall |
2019-09-11 |
| C |
Paradise Lost |
2019-09-12 |
A = [Poets of the Fall, Paradise Lost, Muse, Paradise Lost]
B = [Muse, Paradise Lost, Poets of the Fall]
C = [Paradise Lost, Poets of the Fall, Paradise Lost]
추천이 필요한 사용자($D$)에게 [Poets of the Fall, Paradise Lost]의 구독 목록이 있다고 가정하면, 가장 유사한 콘텐츠 소비 패턴을 가진 A를 찾은 후 [Poets of the Fall, Paradise Lost] 패턴이 나타난 경우, 이후에 A가 소비 된 Muse를 권장합니다. 그러나 위와 같이 성능을 평가할 경우 확정적으로 추천을 하게 되어 추천의 다양성이 떨어지게 됩니다. 그렇기 때문에 CN은 가장 자주 보이는 패턴뿐만 아니라 패턴이 나타나는 모든 경우를 확률 적으로 계산하여 평가됩니다.
Result
CF는 큰 크기의 행렬을 사용한 수학 연산을 기반으로 하기 때문에 수학 계산이 필요합니다. 그러나 CN은 데이터베이스 검색 쿼리와 같은 프로세스를 사용하는 추천 방법이므로 시간 소비는 CF보다 작습니다. 두 알고리즘의 시간 소비를 비교할 때 CF와 CN은 각각 특정 아티스트에게 사용자를 추천하기 위해 평균적으로 2ms와 0.2ms가 필요합니다.
또한 CN은 사용자가 얼마나 많은 특징 정보를 가지고 있느냐에 따라서 정확도가 매우 달라집니다. 이에 따른 비교분석도 진행하기 위해서 CF도 동일하게 진행하였습니다. 결과는 아래와 같습니다.
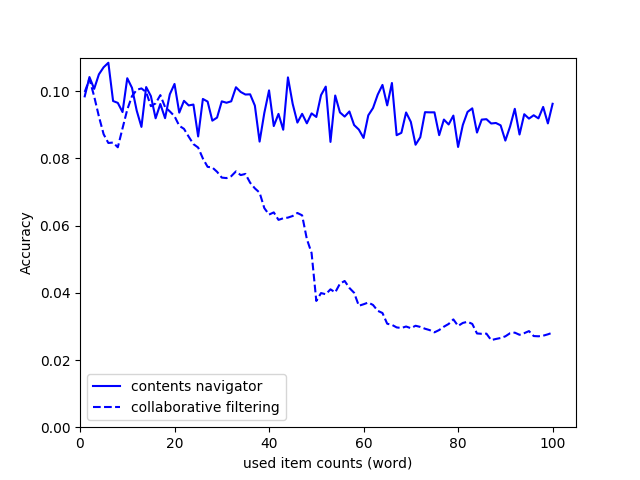
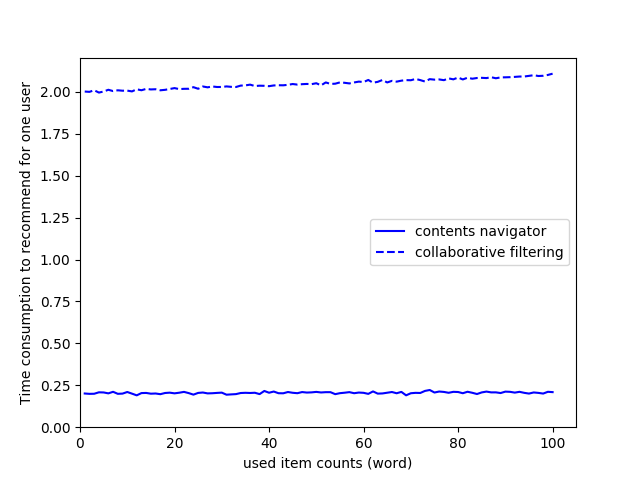
CF의 경우 약 20개의 정보를 포함할때까지는 성능이 보존되지만 더 많은 정보를 포함할수록 점점 성능이 떨어지는 것을 알 수 있습니다. 하지만 CN은 데이터베이스의 검색 쿼리와 같은 프로세스를 사용하는 추천 방법이기 때문에 성능이 지속적으로 보존되는 것을 알 수 있습니다.
결과적으로 CF는 특징 정보의 양에 따라 성능 변동의 폭이 매우 큰 알고리즘인 것을 알 수 있습니다. 하지만 CN은 위의 그래프에서 볼 수 있듯이 추천의 품질이 잘 보존 되는 것을 알 수 있습니다.
즉, 연산량을 고려할 때 CF보다 시간이 CN보다 더 많이 소비됨을 알 수있다. 그러나 CN은 매트릭스 작업이 아닌 일종의 데이터베이스를 쿼리하는 방법이며 온라인 시스템에 매우 빠르게 적응할 수있는 권장 알고리즘입니다. 또한 원본 CF는 수학적 기술만을 기반으로하는 유사성을 기반으로 콘텐츠를 추천합니다. 그러나 복잡한 네트워크 (웹 내의 컨텐츠로 연결된 사람들)의 특성을 사용하여 컨텐츠를 추천하면 추천 성능이 더 높다는 것을 알 수 있습니다.
Conclusion
CF는 콘텐츠 혹은 사물과 사용자 간의 상호 작용만 사용하여 사용자 간의 유사성을 측정 한 다음 각 항목의 선호 확률을 찾아서 추천합니다. 그러나 딥 러닝의 자연어 처리에 자주 사용되는 Sequence-to-Sequence 모델에서 볼 수 있듯이 콘텐츠 혹은 사물의 출현 순서를 고려할 가치가 있으며 관계 특성을 고려할 때 추천 성능이 향상됩니다.
콘텐츠와 콘텐츠의 순서 사이의 관계를 반영하려면 다음과 같은 추가 알고리즘이 필요합니다. 예를 들어, Word2Vec 은 인접한 토큰(컨텐츠) 사이에 관계가 있음을 나타 내기 위해 사용될 수 있으며 Sequence-to-Sequence 토큰(컨텐츠)의 시간적 특성을 표현하는 데 사용될 수 있습니다. 그러나 온라인 추천 시스템에서 이러한 알고리즘을 사용하려면 계산 능력이 높거나 작동하는 데 시간이 오래 걸립니다 .
이 문제는 사용자의 특성에 의해 보상 될 수 있습니다. 사용자가 컨텐츠를 소비함에 따라 소비된 컨텐츠의 주제는 점차적으로 변합니다. 그러나 짧은 기간 동안 컨텐츠의 주제에는 변화가 없으며, 짧은 시간에 동시에 소비되는 컨텐츠는 상관 관계가있는 것으로 간주될 수 있습니다. 또한 사용자는 하나의 서비스에서 컨텐츠라는 항목에 연결되므로 모든 사용자가 느슨하게 연결됩니다. 따라서, 추천이 필요한 사람들의 소비 패턴과 유사한 사람들을 검색하고 그 소비 패턴 이후에 나타나는 컨텐츠를 추천함으로써 많은 계산을 요구하지 않고 합리적인 추천을 할 수 있습니다.
Reference